Which GPU Should You Use to Self-Host LLM

The Float16 team has benchmarked the numbers and summarized them quickly as follows:
TL:DR
GPT-OSS 120B
| GPU Model | Card | Max Concurrent | Min Concurrent |
|---|---|---|---|
| H100 | 1 | 32 | 2 |
| H100 | 2 | 128 | 16 |
| B200 | 1 | 64 | 4 |
| B200 | 2 | 256 | 32 |
| PRO 6000 Blackwell | 1 | 24 | 2 |
| PRO 6000 Blackwell | 2 | 96 | 16 |
GPT-OSS 20B
| GPU Model | Card | Max Concurrent | Min Concurrent |
|---|---|---|---|
| H100 | 1 | 128 | 32 |
| H100 | 2 | 384 | 128 |
| B200 | 1 | 256 | 64 |
| B200 | 2 | 768 | 256 |
| PRO 6000 Blackwell | 1 | 96 | 24 |
| PRO 6000 Blackwell | 2 | 288 | 96 |
Qwen3-30B-A3B
| GPU Model | Card | Max Concurrent | Min Concurrent |
|---|---|---|---|
| H100 | 1 | 128 | 24 |
| H100 | 2 | 320 | 48 |
| B200 | 1 | 256 | 48 |
| B200 | 2 | 640 | 96 |
| PRO 6000 Blackwell | 1 | 96 | 24 |
| PRO 6000 Blackwell | 2 | 288 | 96 |
Typhoon2.1-gemma3-12b
| GPU Model | Card | Max Concurrent | Min Concurrent |
|---|---|---|---|
| H100 | 1 | 64 | 16 |
| H100 | 2 | 128 | 32 |
| B200 | 1 | 128 | 32 |
| B200 | 2 | 256 | 64 |
| PRO 6000 Blackwell | 1 | 48 | 12 |
| PRO 6000 Blackwell | 2 | 96 | 24 |
Full details at https://docs.google.com/spreadsheets/d/1ITmiYOTslh0x4OjmKaB3yk_sVtQOpJMxLCp0KmEvXMA/edit?usp=sharing
Promote Open Source AI Community group from Typhoon team https://www.facebook.com/groups/748411841298712
Long Detailed Explanation
Independent, Control, and Scope Variables
Factors affecting LLM Model Concurrents include 4 factors:
- Input length (Context windows)
- Output length (Max Generate Token)
- GPU Model - The GPU model used
- Number of GPUs
Variables we used for this Benchmark:
- Token Per User must be more than 30 Tokens Per User to count as 1 Concurrent
- Ignore Time To First Token, can take up to 60 seconds
- Ignore duration to complete output generation
Scope
These numbers cannot be used for Linear Scaling. Linear Scaling is possible up to 4 Cards maximum. Beyond that, new calculation formulas are needed, and adding more than 1 Server Node cannot be calculated with Linear Scaling anymore. If you need to calculate more than 1 Node, please contact Float16 team for special cases.
Benchmark Design
This benchmark is intentionally designed with workloads aligned with current use cases. We divide workload into 3 types:
- General Chat
- Web Search Chat or RAG
- Deep Research or Agentic Chat
These 3 workload types affect Input length as follows:
| Workload | ISL (Input Length) | OSL (Output Length) |
|---|---|---|
| Chat | 512 | 1024 |
| Web Search | 8k | 1024 |
| Deep Research | 16k | 1024 |
And we define:
Workload Chat equals Max Concurrent
Workload Deep Research equals Min Concurrent
Testing Method
- Set up 1 LLM Server with vllm
- Then use genai-perf for testing
Tutorial for Self-Hosting LLM
Testing starts by sending Requests for each Workload with the same Request size of 300 Requests but different Concurrents sequentially: 16, 32, 64, 128
genai-perf provides comprehensive results including Time To First Token, Inter Token Time, Min Max P99 P90 P75 which we'll summarize in the next steps.
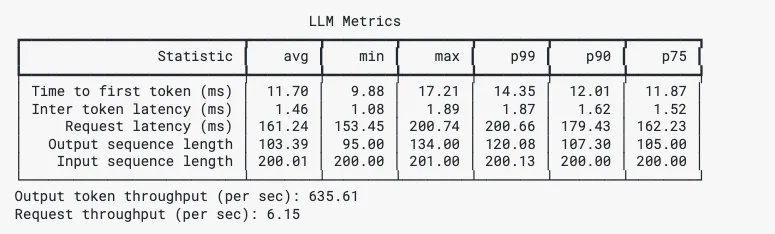
GenAI-Perf Results Example
Models Tested
GPT-OSS-120B & GPT-OSS-20B
Qwen3-30B-A3B
Benchmark for Qwen3-30B-A3B can be referenced for other models in the family like Qwen3-Coder-30B-A3B, etc.
Typhoon2.1-gemma3-12b
Typhoon is a Model specifically for Thai - English languages. Learn more at https://opentyphoon.ai/
Results Summary
Test results went well with some phenomena occurring during testing, such as Super-Linear and Non-Linear phenomena.
Super-Linear Scaling Phenomenon
This phenomenon occurs when doubling GPUs results in more than double the Concurrent capacity.
The cause of Super-Linear Scaling is KV Cache.
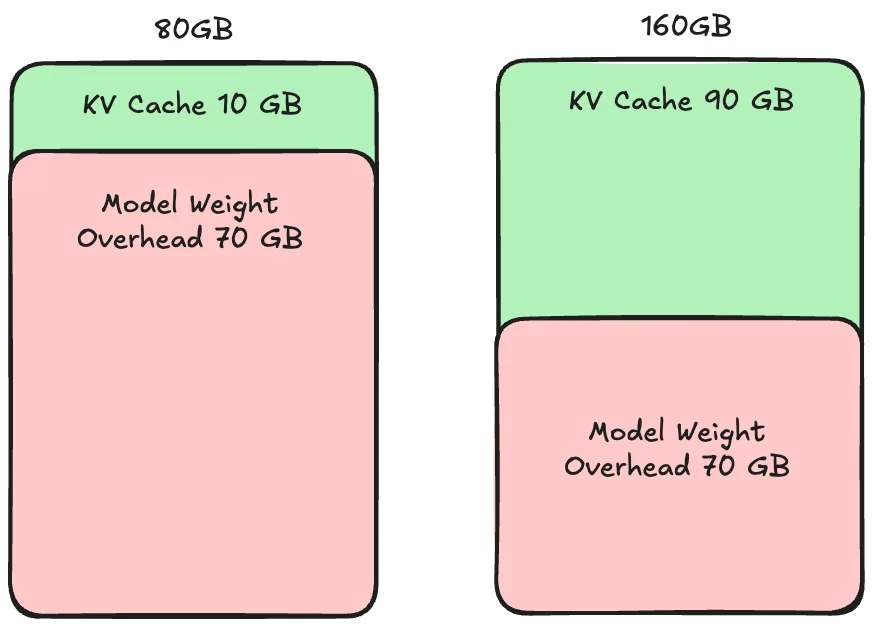
Super-Linear Scaling
KV Cache is the caching portion for processing each Request. If KV Cache size is smaller than Requests, it will slow down processing.
Super-Linear Scaling occurs when 1 GPU has too little KV Cache space for concurrent processing of incoming Requests, causing a Memory bottleneck.
Therefore, adding 1 more GPU helps with both Compute and Memory, resulting in more than 2x performance gain from adding GPU due to benefits from both Compute and Memory.
Non-Linear Scaling Phenomenon
This phenomenon occurs when doubling GPUs or using more than 1 Node results in less than double Concurrent or possibly less than 1x.
The cause of Non-Linear Scaling is Inter-Network Bandwidth between Nodes or between Cards.

Comparing High Bandwidth and Low Bandwidth
Non-Linear Scaling occurs when connecting more than 1 GPU or more than 1 Node. Especially connecting more than 1 Node requires Synchronization between Nodes for continuous processing. The faster and more Nodes there are, Synchronization must be done across all Nodes. Therefore, if Network Bandwidth and Speed are slower than Synchronization, performance will be limited by that Synchronization.
Final Thoughts
We hope everyone enjoys using GPU for Self-Hosting LLM. If you have questions, you can ask anytime via Float16 Discord or Float16 Facebook Messenger.
Notes
B200 and PRO 6000 Blackwell results are theoretical calculations extrapolated from H100 results, which may have deviations in actual testing.
The presented numbers (B200, PRO 6000 Blackwell) are minimum estimated numbers. Actual testing has a high chance of getting numbers higher than presented. These numbers can be used as Guidelines for initial assessment.
Contact
- Medium : Float16.cloud
- Facebook : Float16.cloud
- X : Float16.cloud
- Discord : Float16.cloud
- Youtube : Float16.cloud
- Email : business[at]float16.cloud