Ekstraksi Data dari Gambar Menggunakan Gemma3

Untuk ekstraksi data dari gambar seperti kuitansi, kartu identitas, atau formulir kertas, metode tradisional sering menggunakan OCR (Optical Character Recognition) dikombinasikan dengan aturan atau regex untuk mengekstrak data. Ini rumit dan sulit ketika format data berubah.
Pada kenyataannya, kita memiliki pilihan lain: LLM Multimodal yang dapat "memahami gambar" dan "menjawab pertanyaan" secara langsung.
Konsep
LLM Multimodal dapat memproses teks dan gambar secara bersamaan, memungkinkan kita memasukkan gambar bersama dengan prompt seperti:
Gambar ini adalah kuitansi restoran. Silakan ekstrak data ke dalam JSON: nama restoran, tanggal, item makanan, jumlah total
Contoh Kode
Model
Untuk putaran ini, kita akan mencoba menggunakan gemma3-12b-vision
Anda dapat mengikuti Getting Started di README untuk siapa saja yang ingin mencoba deploy model sendiri
Kode
client-gemma3.ts
- Tetapkan prompt yang jelas tentang apa gambar ini, field apa yang diperlukan dengan contoh, apa yang harus dilakukan jika tidak ditemukan, dan tentukan harus mengembalikan dalam format JSON saja. Di sini kita juga akan memberitahunya untuk melihat
categoryuntuk menentukan apa itu. Jikainvoice, maka ekstrak field yang kita inginkan, tetapi jika tidak, beritahu kita apa itu.
This is an image of a document. Please analyze the document and return a JSON object that strictly follows the schema below:
{
"category": string, // Document category: "invoice", "receipt", or "other-[description]"
"result": object | null // Invoice data if category is "invoice", otherwise null
}
If the document category is "invoice", return the result as:
{
"category": "invoice",
"result": {
"invoice_number": string, // e.g. "INV-2024-00123"
"invoice_date": string, // Date as shown in document (any format: DD/MM/YYYY, MM-DD-YYYY, YYYY-MM-DD, etc.)
"due_date": string | null, // Date as shown in document (any format) or null if not found
"total_amount": number | null, // Final total amount (e.g. 1234.50) in INR
"items": [
{
"description": string, // Name of the product or service
"quantity": number | null,
"unit_price": number | null,
"line_total": number | null
}
]
}
}
If the document category is NOT "invoice", return the result as:
{
"category": "receipt" | "other-[description]",
"result": null
}
DOCUMENT CATEGORY GUIDELINES:
- "invoice": Only tax invoices, billing invoices, commercial invoices
- "receipt": Payment receipts, transaction receipts
- "other-[description]": For any other content, describe what you see after "other-"
Examples: "other-id_card", "other-child_photo", "other-certificate", "other-bill", "other-menu", "other-text_document"
IMPORTANT INSTRUCTIONS:
- Only extract invoice data if the document category is clearly "invoice"
- For receipts, use exactly "receipt" as the category
- For anything else, use "other-" followed by a brief English description of what you see
- For dates, extract them exactly as they appear in the document - do not convert or reformat
- For all non-invoice documents, set result to null
- Do not guess or fabricate values
- Return ONLY the JSON object directly. Do not wrap it in markdown code blocks (\`\`\`json\`\`\`)
- Do not include any explanation, comments, or extra text before or after the JSON
- Your response should start with { and end with }
- The response must be valid JSON that can be parsed directly
- Kirim gambar melalui tipe
image_urldalam content message bolak-balik
const { data } = await axios.post(
`${process.env.BASE_URL}/chat/completions`,
{
model: "gemma3-12b-vision",
messages: [
{
role: "user",
content: [
{
type: "text",
text: prompt,
},
{
type: "image_url",
image_url: { url: `data:image/jpeg;base64,${image}` },
},
],
},
],
},
{
headers: {
Authorization: `Bearer ${process.env.API_KEY}`,
"Content-Type": "application/json",
},
}
);
client-openai.ts
Untuk kasus menggunakan Model lain yang mendukung OpenAI Completions dan Multimodal
Hasil
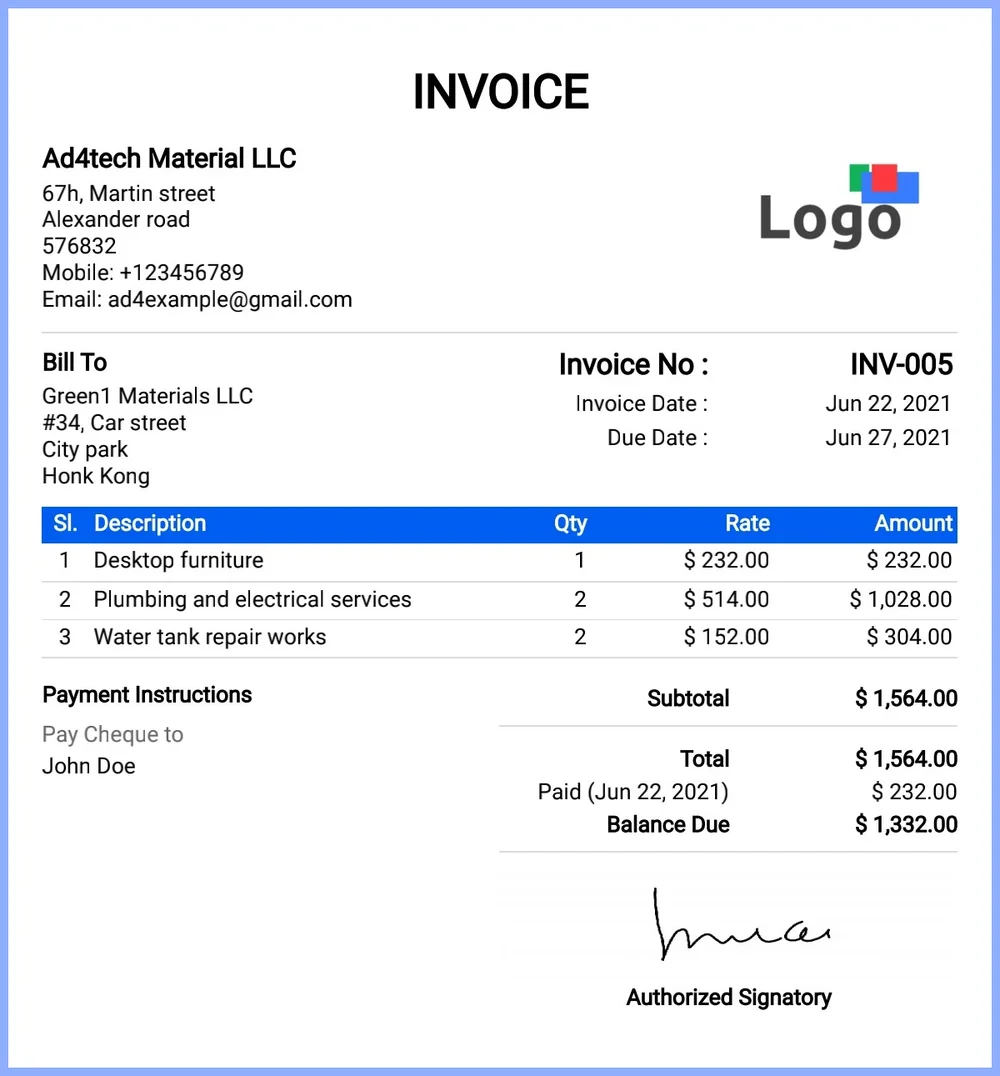
{
"category": "invoice",
"result": {
"invoice_number": "INV-005",
"invoice_date": "Jun 22, 2021",
"due_date": "Jun 27, 2021",
"total_amount": 1564,
"items": [
{
"description": "Desktop furniture",
"quantity": 1,
"unit_price": 232,
"line_total": 232
},
{
"description": "Plumbing and electrical services",
"quantity": 2,
"unit_price": 514,
"line_total": 1028
},
{
"description": "Water tank repair works",
"quantity": 2,
"unit_price": 152,
"line_total": 304
}
]
}
}

{
"category": "invoice",
"result": {
"invoice_number": "100",
"invoice_date": "1/30/23",
"due_date": "1/30/23",
"total_amount": 420,
"items": [
{
"description": "20\" x 30\" hanging frames",
"quantity": 10,
"unit_price": 15,
"line_total": 150
},
{
"description": "5\" x 7\" standing frames",
"quantity": 50,
"unit_price": 5,
"line_total": 250
}
]
}
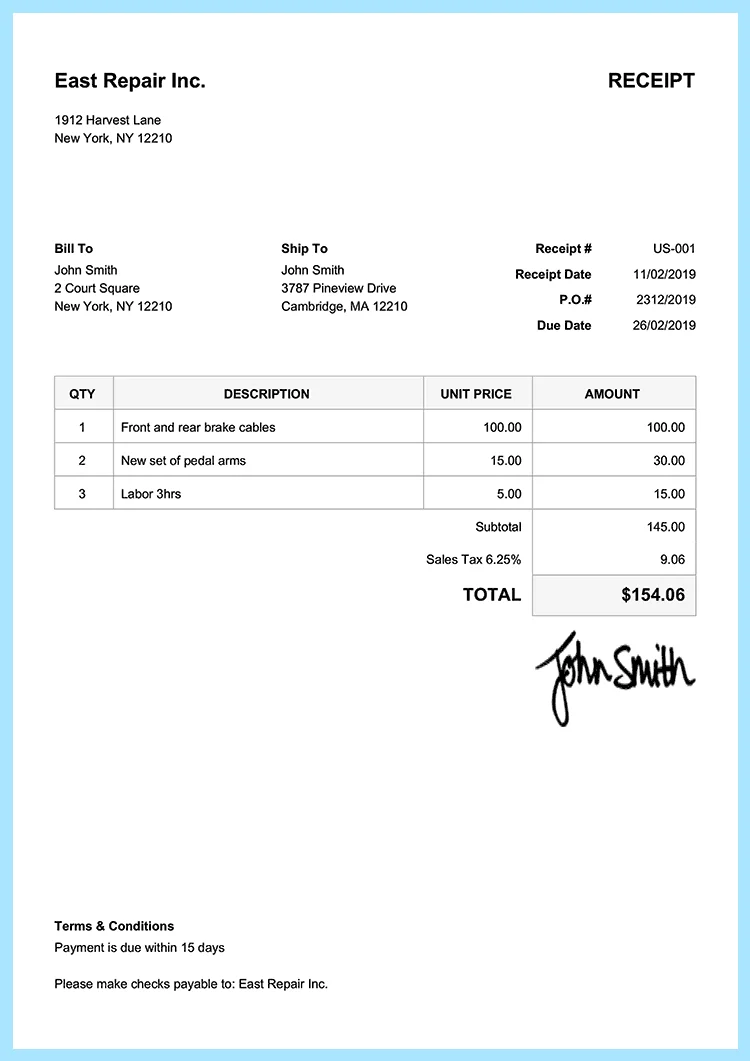
{
"category": "receipt",
"result": null
}
Keuntungan
- Bekerja dengan berbagai format (bahkan jika layout berubah)
- Dapat menentukan data yang diinginkan melalui prompt
- Tidak perlu menulis regex atau template khusus dokumen
- Dapat menambahkan kondisi seperti jika a maka ekstrak b
- Dapat melakukan klasifikasi/validasi
Perhatian
- Biaya relatif tinggi (dikenakan biaya per token)
- Akurasi tergantung pada prompt dan kejelasan gambar
- Harus memiliki fallback atau validasi jika model memberikan jawaban salah
Dibandingkan dengan Pendekatan OCR
- OCR: Konversi gambar ke teks
- OCR Post-processing: Tingkatkan teks yang diperoleh dari OCR agar lebih akurat
- Text Extraction & Cleaning: Ekstrak teks penting dan bersihkan data
- Document Structure Understanding: Pahami struktur dokumen (kuitansi, faktur, laporan persetujuan)
- Named Entity Recognition (NER): Identifikasi nama perusahaan, tanggal, jumlah, nomor dokumen
Kesimpulan
Menggunakan Multimodal LLM untuk ekstraksi data dari gambar adalah pendekatan yang sangat baik, terutama ketika dokumen memiliki banyak field dan kita hanya ingin mengekstrak field tertentu, layout mungkin tidak konsisten, atau ada kondisi tertentu untuk ekstraksi data. Kita dapat mengontrolnya melalui prompt tanpa membangun sistem parsing yang kompleks. Ini berarti kita tidak perlu lagi terpaku pada ide bahwa jenis pekerjaan ini harus hanya menggunakan OCR dan kemudian duduk menulis regex atau menganalisis lebih lanjut untuk mengekstrak data yang benar-benar kita inginkan.
Contoh yang diberikan adalah ekstraksi data sederhana, tetapi pada kenyataannya, ada banyak pendekatan lain yang dapat kita ambil. Kita dapat menambahkan kondisi tertentu, menggunakannya untuk Klasifikasi/Validasi.
Float16
Platform resource GPU terkelola untuk developer. Rasakan serverless GPU termurah dalam mode spot dan GPU endpoint tercepat dalam mode deploy.
Terhubung dengan kami:
- Medium : Float16.cloud
- Facebook : Float16.cloud
- X : Float16.cloud
- Discord : Float16.cloud
- Youtube : Float16.cloud