GPU Mana Yang Harus Anda Gunakan untuk Self-Host LLM

Tim Float16 telah melakukan benchmark angka dan merangkumnya dengan cepat sebagai berikut:
TL:DR
GPT-OSS 120B
| GPU Model | Card | Max Concurrent | Min Concurrent |
|---|---|---|---|
| H100 | 1 | 32 | 2 |
| H100 | 2 | 128 | 16 |
| B200 | 1 | 64 | 4 |
| B200 | 2 | 256 | 32 |
| PRO 6000 Blackwell | 1 | 24 | 2 |
| PRO 6000 Blackwell | 2 | 96 | 16 |
GPT-OSS 20B
| GPU Model | Card | Max Concurrent | Min Concurrent |
|---|---|---|---|
| H100 | 1 | 128 | 32 |
| H100 | 2 | 384 | 128 |
| B200 | 1 | 256 | 64 |
| B200 | 2 | 768 | 256 |
| PRO 6000 Blackwell | 1 | 96 | 24 |
| PRO 6000 Blackwell | 2 | 288 | 96 |
Qwen3-30B-A3B
| GPU Model | Card | Max Concurrent | Min Concurrent |
|---|---|---|---|
| H100 | 1 | 128 | 24 |
| H100 | 2 | 320 | 48 |
| B200 | 1 | 256 | 48 |
| B200 | 2 | 640 | 96 |
| PRO 6000 Blackwell | 1 | 96 | 24 |
| PRO 6000 Blackwell | 2 | 288 | 96 |
Typhoon2.1-gemma3-12b
| GPU Model | Card | Max Concurrent | Min Concurrent |
|---|---|---|---|
| H100 | 1 | 64 | 16 |
| H100 | 2 | 128 | 32 |
| B200 | 1 | 128 | 32 |
| B200 | 2 | 256 | 64 |
| PRO 6000 Blackwell | 1 | 48 | 12 |
| PRO 6000 Blackwell | 2 | 96 | 24 |
Detail lengkap di https://docs.google.com/spreadsheets/d/1ITmiYOTslh0x4OjmKaB3yk_sVtQOpJMxLCp0KmEvXMA/edit?usp=sharing
Promosikan grup Open Source AI Community dari tim Typhoon https://www.facebook.com/groups/748411841298712
Penjelasan Detail Panjang
Variabel Independen, Kontrol, dan Lingkup
Faktor yang mempengaruhi LLM Model Concurrents meliputi 4 faktor:
- Panjang input (Context windows)
- Panjang output (Max Generate Token)
- GPU Model - Model GPU yang digunakan
- Jumlah GPU
Variabel yang kami gunakan untuk Benchmark ini:
- Token Per User harus lebih dari 30 Tokens Per User untuk dihitung sebagai 1 Concurrent
- Abaikan Time To First Token, dapat memakan waktu hingga 60 detik
- Abaikan durasi untuk menyelesaikan generasi output
Lingkup
Angka-angka ini tidak dapat digunakan untuk Linear Scaling. Linear Scaling dimungkinkan hingga maksimal 4 Card. Lebih dari itu, formula perhitungan baru diperlukan, dan menambahkan lebih dari 1 Server Node tidak dapat dihitung dengan Linear Scaling lagi. Jika Anda perlu menghitung lebih dari 1 Node, silakan hubungi tim Float16 untuk kasus khusus.
Desain Benchmark
Benchmark ini sengaja dirancang dengan workload yang selaras dengan use case saat ini. Kami membagi workload menjadi 3 jenis:
- General Chat
- Web Search Chat atau RAG
- Deep Research atau Agentic Chat
3 jenis workload ini mempengaruhi panjang Input sebagai berikut:
| Workload | ISL (Input Length) | OSL (Output Length) |
|---|---|---|
| Chat | 512 | 1024 |
| Web Search | 8k | 1024 |
| Deep Research | 16k | 1024 |
Dan kami mendefinisikan:
Workload Chat sama dengan Max Concurrent
Workload Deep Research sama dengan Min Concurrent
Metode Testing
- Setup 1 LLM Server dengan vllm
- Kemudian gunakan genai-perf untuk testing
Tutorial untuk Self-Hosting LLM
Testing dimulai dengan mengirim Requests untuk setiap Workload dengan ukuran Request yang sama yaitu 300 Requests tetapi Concurrent berbeda secara berurutan: 16, 32, 64, 128
genai-perf memberikan hasil komprehensif termasuk Time To First Token, Inter Token Time, Min Max P99 P90 P75 yang akan kami rangkum di langkah selanjutnya.
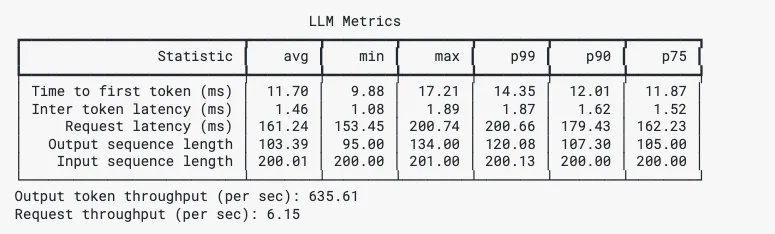
Contoh Hasil GenAI-Perf
Model yang Ditest
GPT-OSS-120B & GPT-OSS-20B
Qwen3-30B-A3B
Benchmark untuk Qwen3-30B-A3B dapat direferensikan untuk model lain dalam keluarga seperti Qwen3-Coder-30B-A3B, dll.
Typhoon2.1-gemma3-12b
Typhoon adalah Model khusus untuk bahasa Thai - English. Pelajari lebih lanjut di https://opentyphoon.ai/
Ringkasan Hasil
Hasil test berjalan dengan baik dengan beberapa fenomena terjadi selama testing, seperti fenomena Super-Linear dan Non-Linear.
Fenomena Super-Linear Scaling
Fenomena ini terjadi ketika menggandakan GPU menghasilkan lebih dari dua kali lipat kapasitas Concurrent.
Penyebab Super-Linear Scaling adalah KV Cache.
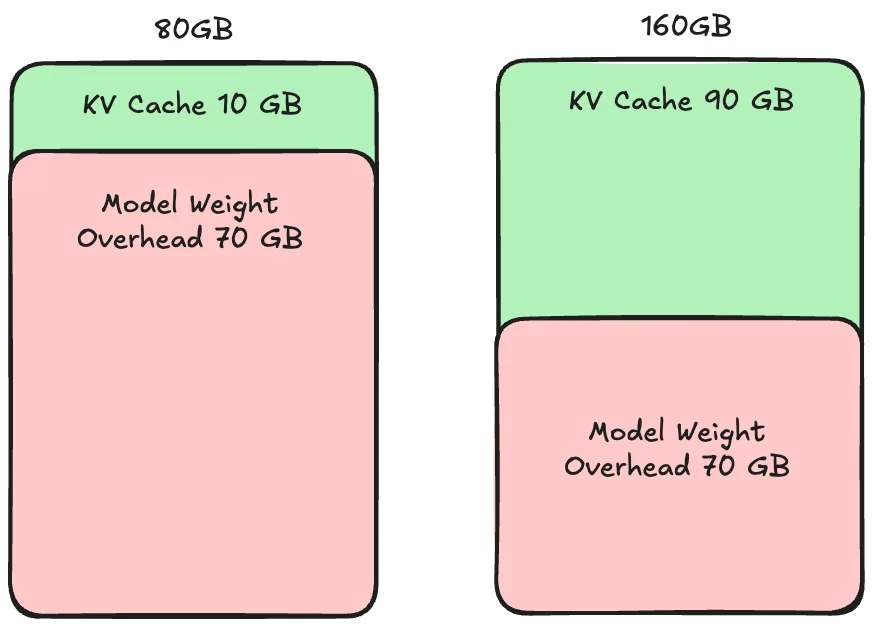
Super-Linear Scaling
KV Cache adalah bagian caching untuk memproses setiap Request. Jika ukuran KV Cache lebih kecil dari Requests, ini akan memperlambat pemrosesan.
Super-Linear Scaling terjadi ketika 1 GPU memiliki ruang KV Cache terlalu sedikit untuk pemrosesan concurrent dari Requests yang masuk, menyebabkan bottleneck Memory.
Oleh karena itu, menambahkan 1 GPU lagi membantu dengan Compute dan Memory, menghasilkan gain performa lebih dari 2x dari menambahkan GPU karena manfaat dari Compute dan Memory.
Fenomena Non-Linear Scaling
Fenomena ini terjadi ketika menggandakan GPU atau menggunakan lebih dari 1 Node menghasilkan kurang dari dua kali lipat Concurrent atau mungkin kurang dari 1x.
Penyebab Non-Linear Scaling adalah Inter-Network Bandwidth antara Node atau antara Card.

Membandingkan High Bandwidth dan Low Bandwidth
Non-Linear Scaling terjadi ketika menghubungkan lebih dari 1 GPU atau lebih dari 1 Node. Terutama menghubungkan lebih dari 1 Node memerlukan Synchronization antara Node untuk pemrosesan berkelanjutan. Semakin cepat dan semakin banyak Node ada, Synchronization harus dilakukan di semua Node. Oleh karena itu, jika Network Bandwidth dan Speed lebih lambat dari Synchronization, performa akan dibatasi oleh Synchronization itu.
Pemikiran Akhir
Kami berharap semua orang menikmati menggunakan GPU untuk Self-Hosting LLM. Jika Anda memiliki pertanyaan, Anda dapat bertanya kapan saja melalui Float16 Discord atau Float16 Facebook Messenger.
Catatan
Hasil B200 dan PRO 6000 Blackwell adalah perhitungan teoritis yang diekstrapolasi dari hasil H100, yang mungkin memiliki deviasi dalam testing aktual.
Angka yang disajikan (B200, PRO 6000 Blackwell) adalah angka estimasi minimum. Testing aktual memiliki kemungkinan tinggi mendapatkan angka lebih tinggi dari yang disajikan. Angka-angka ini dapat digunakan sebagai Pedoman untuk penilaian awal.
Kontak
- Medium : Float16.cloud
- Facebook : Float16.cloud
- X : Float16.cloud
- Discord : Float16.cloud
- Youtube : Float16.cloud
- Email : business[at]float16.cloud