เจาะลึกการทำ GPU Benchmark สำหรับงาน AI: จาก Consumer Grade สู่ Enterprise Solutions

AI Benchmark ทำไมถึงสำคัญและแตกต่างจาก Benchmark ในปัจจุบัน
หลังจาก ChatGPT เปิดตัวตอนปี 2022 ซึ่งมี AI ให้เลือกใช้งานผ่าน Cloud จำนวนมากและเข้าถึงได้ง่าย แต่อีกมุมหนึ่งคือ AI ที่เปิดให้สามารถดาวน์โหลดได้ฟรีจาก Huggingface, Modelscope ตัวอย่าง Model เช่น Llama จาก Meta (Facebook), Gemma จาก Alphabet (Google), Grok จาก X, GPT-OSS จาก OpenAI, Qwen จาก Alibaba, Deepseek จาก Deepseek หรือแม้แต่ Typhoon จากทีม SCB10X
ส่งผลให้ คนทั่วไปหรือนักพัฒนาสามารถรัน AI บนคอมพิวเตอร์ของตัวเองได้ แต่สิ่งที่ต้องแลกมาด้วยนั้นคือพลังในการประมวลผลที่ต้องการอย่างมหาศาล ไม่ต่างจากการ Render Graphic ที่เราคุ้นเคย เช่น การทำ 3D CAD, Game Engine หรือแม้แต่ 3D Animation
จึงหนีไม่พ้นที่เราต้องใช้ GPU ในการประมวลผล AI เริ่มจากการใช้ GPU รุ่นเล็ก ๆ เช่น RTX 3050 เอามารัน AI เป็นงานอดิเรก จนไปถึงการใช้งาน GPU จำนวนมากกว่า 1 GPU ในการประมวลผล AI
ไม่ว่าจะเป็นการนำ RTX 5090 มาต่อกันแบบ DIY ก็ดี หรือไปจนถึง DGX Spark, H100, H200, B200 ที่ออกแบบมาเพื่อรองรับการประมวลผลมากกว่า 1 ใบอย่างมีประสิทธิภาพ
และเมื่อรุ่นของ GPU มีผลกับ “ความเร็ว” ในการประมวลผลแล้ว จึงเกิดคำถามสุดคลาสสิกขึ้นมาว่า
GPU รุ่นนี้รัน AI ตัวนี้ได้มั้ย
สำหรับใครที่คุ้นกับคำถามนี้ก็จะ Flash back ย้อนวันวานทันทีว่า สิ่งนี้ก็เคยเกิดขึ้นกับวงการเกมส์เมื่อ 10 - 20 ปีก่อนเหมือนกัน ที่เวลาเกมส์ออกใหม่แล้วจะต้องถามว่า GPU รุ่นนี้เล่นเกมส์ที่ออกใหม่ได้ไหม
และยังเป็นช่องว่างที่ AI Benchmark ในปัจจุบันยังไม่สามารถตอบได้คือ
1. AI Benchmark วัดแค่คะแนน ไม่ได้วัดจากการรัน AI จริง
2. AI Benchmark ไม่ได้เปิดเผยวิธีคำนวนคะแนน ทำให้อ้างอิงต่อไม่ได้
3. AI Benchmark ไม่ได้เปิดเผยวิธีการรัน AI ว่าเทียบจากอะไรหรือวัดประสิทธิภาพของอะไร
4. AI Benchmark ไม่ได้เทียบจาก Real world task เช่น LLM, Image Gen, Video Gen และ อื่น ๆ
การทดสอบ Benchmark AI Model
การทดสอบ Benchmark ต่อไปนี้ เป็นการทดสอบที่ใช้มาตรฐานเดียวกับ Gold standard ที่ใช้ทดสอบระดับเดียวกับที่บริษัทชั้นนำด้านการพัฒนา AI ใช้กันแบบแพร่หลาย
ไม่ว่าจะเป็นการใช้งาน vLLM แทนที่ Ollama ในการทดสอบ, Diffusers แทนที่ ComfyUI เพื่อให้ได้ความเสถียรและสามารถจะทดสอบซ้ำได้อย่างมีประสิทธิภาพ, genai-perf สำหรับการทำ load test จำลองผู้ใช้งานจำนวนมากพร้อมกัน
AI Model สำหรับ AI Benchmark
AI ที่เราทำการทดสอบมีด้วยกันทั้งสิ้น 6 ประเภท ได้แก่
1. Text-to-Text (ถามด้วยตัวอักษรตอบด้วยตัวอักษร ลักษณะเดียวกับ GPT3.5)
- Qwen3-4B-Instruct-2507-FP8, typhoon2.5-qwen3-4b, gpt-oss-20b
2. Vision-to-Text (ถามด้วยรูปภาพหรือตัวอักษร และตอบด้วยตัวอักษร ลักษณะเดียวกับ GPT-4o)
- Qwen3-VL-4B-Instruct-FP8, Qwen3-VL-8B-Instruct-FP8, typhoon-ocr-3b
3. Text-to-Image (ลักษณะเดียวกับ Nano Banana)
- Qwen-Image
4. Image-to-Image (ลักษณะเดียวกับ Nano Banana)
- Qwen-Image-Edit
5. Text-to-Video (ลักษณะเดียวกับ Sora)
- Wan2.2-5B, Wan2.2-14B
6. Audio-to-Text (ถอดความจากไฟล์เสียงให้เป็นตัวอักษร)
- Typhoon-ASR
Hardware
1. PC
RAM 64 GB
Windows 11 (25H2) - WSL Ubuntu 24.04 LTS
Storage SSD NVMe 1 TB
GPU
- NVIDIA RTX 3050
- NVIDIA RTX 4060
- NVIDIA RTX 5060
- NVIDIA RTX 5070
- NVIDIA RTX 5080
- NVIDIA RTX 5090
2. HGX Server
RAM 2 TB
Ubuntu 24.04 LTS
Storage Raid-0 28TB
GPU
- NVIDIA L4
- NVIDIA L40s
- NVIDIA H100
3. DGX Spark
Software
vLLM v0.11 -> container image nvcr.io/nvidia/vllm:25.11-py3
Diffuser main (19 Nov 2025) -> AI Library for Image and Video
Pytorch v2.8.0 -> container image nvcr.io/nvidia/pytorch:25.10-py3
Genai-perf v.0.0.16 -> Load test software
ผลการทดสอบกลุ่ม Text-to-Text, Vision-to-Text
การทดสอบกลุ่มที่ 1 เป็นการรัน AI ที่ตอบโต้กลับมาเป็น Text เท่านั้น
เราสามารถเห็นการใช้งาน AI ในลักษณะดังกล่าวกับ Application เช่น ChatGPT, Gemini, Anthropic, Cluade code หรือ Copilot เป็นต้น
การตั้งค่า
- ความยาวของ Context ที่ 512 token และความยาวของ Output ที่ 1024 token
Model ที่ทำการทดสอบได้แก่ Model Qwen3-4B-Instruct-2507-FP8, Qwen3-VL-4B-Instruct-FP8, Qwen3-VL-8B-Instruct-FP8, Typhoon-ocr-3b, typhoon2.5-qwen3-4b และ GPT-oss-20b ซึ่งมีขนาดอยุ่ที่ 3B, 4B, 8B และ 20B เหมาะสำหรับงานง่าย ๆ เช่น การถามตอบทั่วไป, การแยกชื่อ,ที่อยู่,เบอร์จากประโยค, การอ่านตัวอักษรหรือหาคำจากรูปภาพ และอื่น ๆ
| Model | Type | RTX 3050 | RTX 4060 | RTX 5060 | RTX 5070 | RTX 5080 | RTX 5090 | DGX Spark | L4 | L40s | H100 |
|---|---|---|---|---|---|---|---|---|---|---|---|
| Qwen3-4B-Instruct-2507-FP8 | Text | 141.1 | 174.87 | 189.99 | N/A1 | N/A1 | N/A1 | N/A1 | N/A1 | N/A1 | N/A1 |
| Qwen3-VL-4B-Instruct-FP8 | Text + Image | N/A2 | N/A2 | N/A2 | 707.7 | 895.07 | 1,005.24 | 1,236.83 | 445.47 | 1,049.57 | 7,789.64 |
| Qwen3-VL-8B-Instruct-FP8 | Text + Image | N/A2 | N/A2 | N/A2 | N/A2 | 403.08 | 867.69 | 971.5 | 297.53 | 745.98 | 7,035.18 |
| Typhoon-ocr-3b | Text + Image | N/A2 | N/A2 | N/A2 | 330.62 | 393.51 | 1576.74 | 695.52 | 878.73 | 2,419.41 | 14,018.87 |
| Typhoon2.5-qwen3-4b | Text | N/A2 | N/A2 | N/A2 | 432.83 | 1012.9 | 1445.77 | 1105.46 | 529.12 | 1,523.01 | 9,930.86 |
| GPT-oss-20b | Text | N/A2 | N/A2 | N/A2 | N/A2 | N/A2 | 1337.89 | 1093.84 | 542.15 | 910.17 | 8,553.21 |
* DGX Spark และ H100 วัดที่ 128 ผู้ใช้งานพร้อมกัน นอกจากนั้นวัดที่ 16 ผู้ใช้งานพร้อมกัน
N/A1 หมายถึง Model ดังกล่าวซ้ำซ้อนกับ Model อื่น ๆ ที่อยู่ในประเภทเดียวกันและมีความฉลาดใกล้เคียงกัน แต่รองรับประเภทของ Input ได้มากกว่า เช่น รองรับ Text + Vision
N/A2 หมายถึง GPU ดังกล่าวไม่สามารถรัน Model นั้น ๆ ได้ เนื่องจาก VRAM มีไม่เพียงพอ
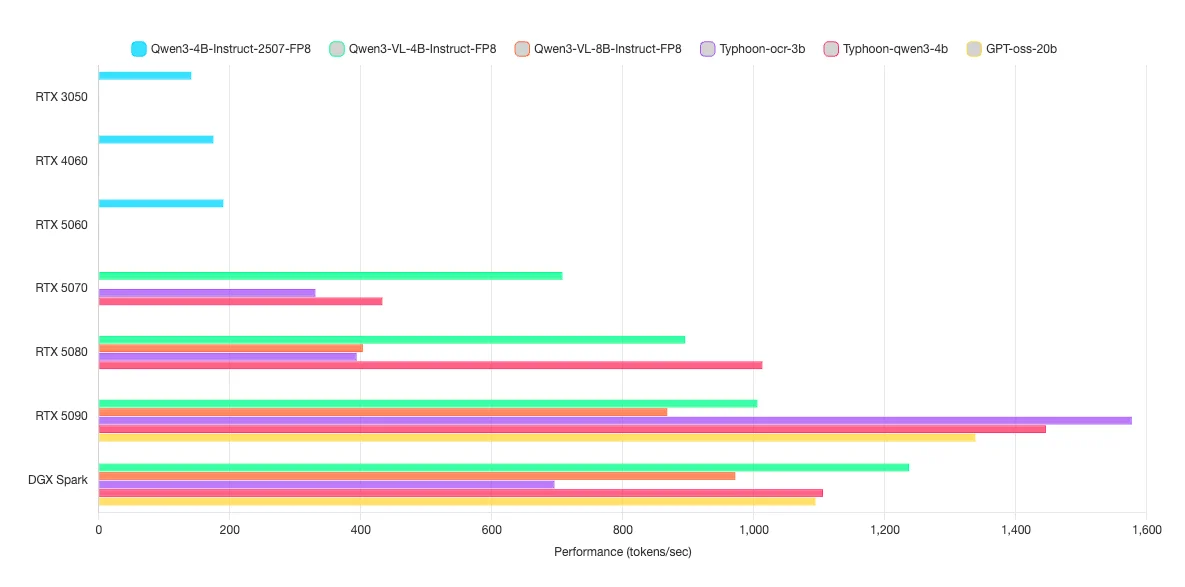
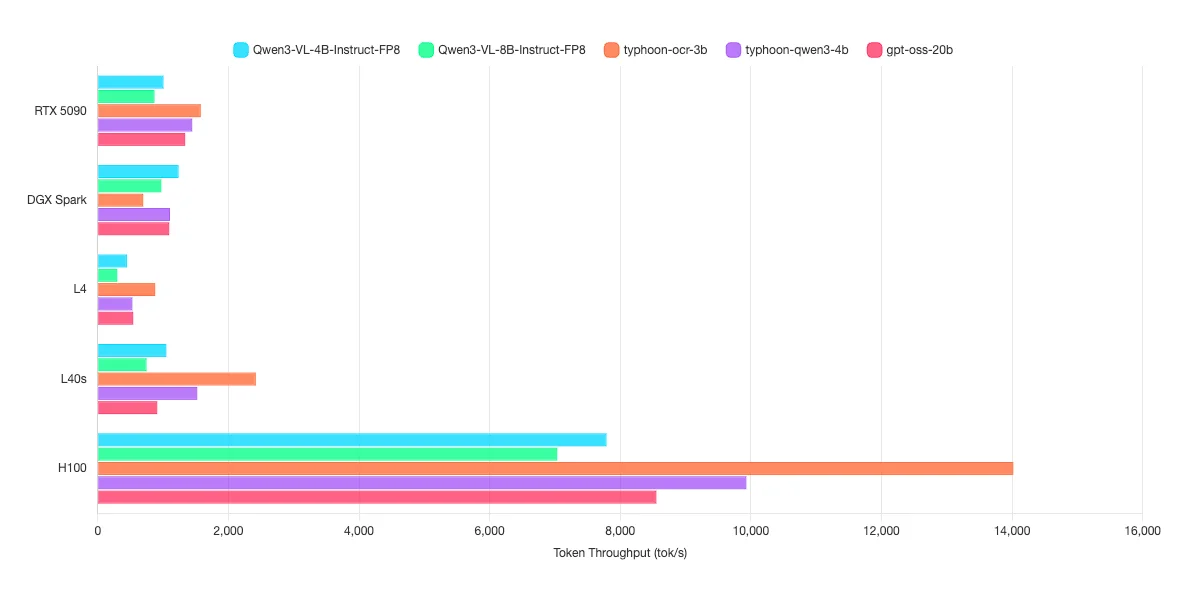
ตัวเลขที่แต่ละ Model ได้ออกมานั้น คือตัวเลขของ token per seconds (tok/s) นั้นเอง ค่ายิ่งเยอะยิ่งดี โดยค่านี้จะสื่อถือความเร็วในการตอบกลับวัดด้วยหน่วยคำ ต่อ 1 วินาที
โดย tok/s ที่วัดผลถูกวัดจากการใช้งานพร้อมกันที่ 16 ผู้ใช้งานพร้อมกัน ตัวอย่างเช่น Qwen3-4B-Instruct-2507-FP8 ด้วย RTX 3050 ได้ tok/s อยู่ที่ 141.1 ต่อ 16 users แต่ละ user จะเฉลี่ยรับรู้ tok/s ที่คนละ 141.1/16 = 8.82 tok/s
สำหรับการ visualize tok/s ว่าเร็วแค่ไหนถึงจะเพียงพอ สามารถทดสอบ visualization ได้ผ่าน เว็บไซต์
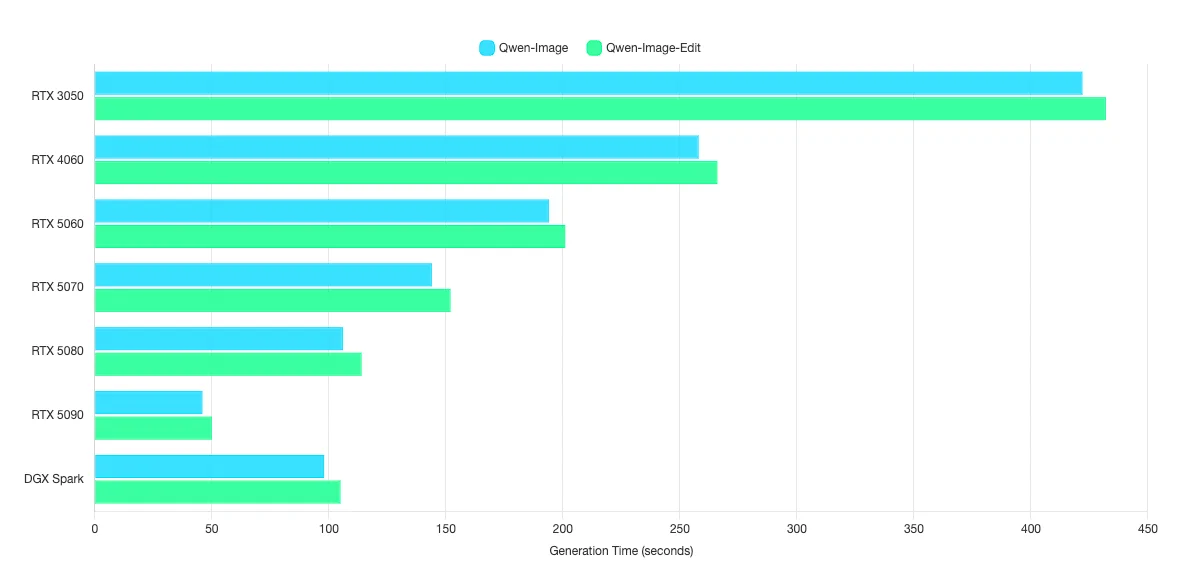
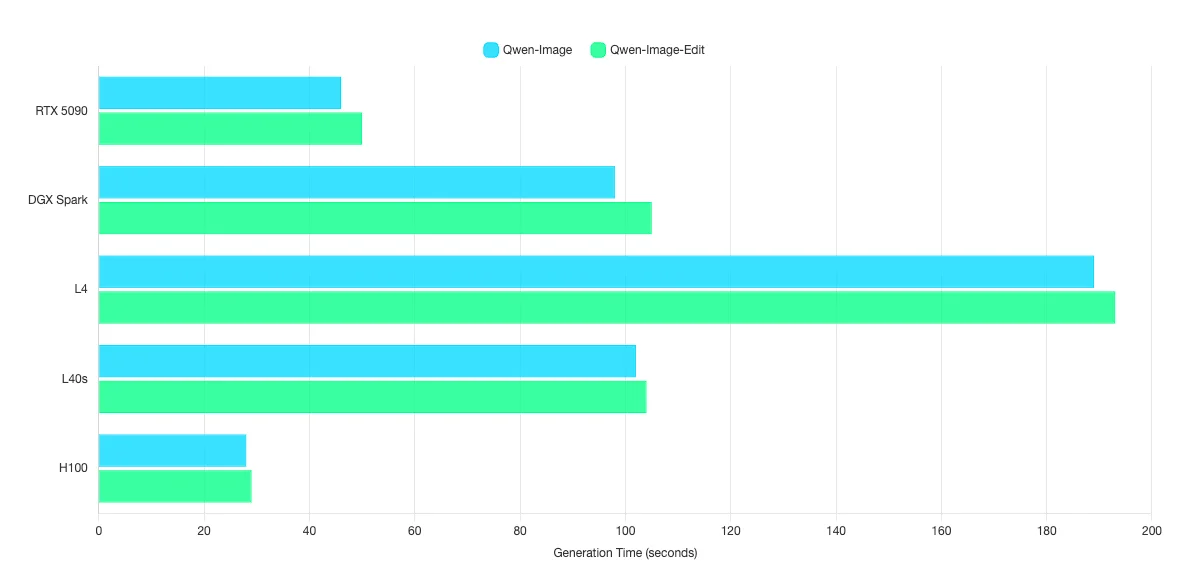
ผลการทดสอบกลุ่ม Text-to-Image, Image-to-Image
สำหรับการทดสอบกลุ่มที่ 2 เป็นการรัน AI ที่ตอบโต้กลับมาเป็น Image เท่านั้น
เราสามารถเห็นการใช้งาน AI ในลักษณะดังกล่าวกับ Application เช่น ChatGPT, Gemini Nano Banana เป็นต้น
| Model | Type | RTX 3050 | RTX 4060 | RTX 5060 | RTX 5070 | RTX 5080 | RTX 5090 | DGX Spark | L4 | L40s | H100 |
|---|---|---|---|---|---|---|---|---|---|---|---|
| Qwen-Image | Image Gen | 422 | 258 | 194 | 144 | 106 | 46 | 98 | 189 | 102 | 28 |
| Qwen-Image-Edit | Image Gen | 432 | 266 | 201 | 152 | 114 | 50 | 105 | 193 | 104 | 29 |
ตัวเลขที่แต่ละ Model ได้ออกมานั้น คือตัวเลขของเวลาที่ใช้ในการประมวลผล 1 รูปภาพในหน่วยของวินาที ค่ายิ่งน้อยยิ่งดี โดยค่านี้จะสื่อถือความเร็วในการประมวลผลรูปภาพ 1 รูปภาพตั้งแต่ต้นจนจบ
การตั้งค่า
- สร้างรูปภาพที่ความละเอียด Full-HD (1080p)
- Model weight ใช้ FP8 และ INT8
- ไม่ใช้เทคนิค Caching หรือ Distillation
ตัวอย่างจาก Image Generation (Text-to-Image)



ตัวอย่างจาก Image Editing (Image-to-Image)




ผลการทดสอบกลุ่ม Text-to-Video
สำหรับการทดสอบกลุ่มที่ 3 เป็นการรัน AI ที่ตอบโต้กลับมาเป็น Video เท่านั้น
เราสามารถเห็นการใช้งาน AI ในลักษณะดังกล่าวกับ Application เช่น OpenAI Sora, Google VEO เป็นต้น
| Model | Type | RTX 3050 | RTX 4060 | RTX 5060 | RTX 5070 | RTX 5080 | RTX 5090 | DGX Spark | L4 | L40s | H100 |
|---|---|---|---|---|---|---|---|---|---|---|---|
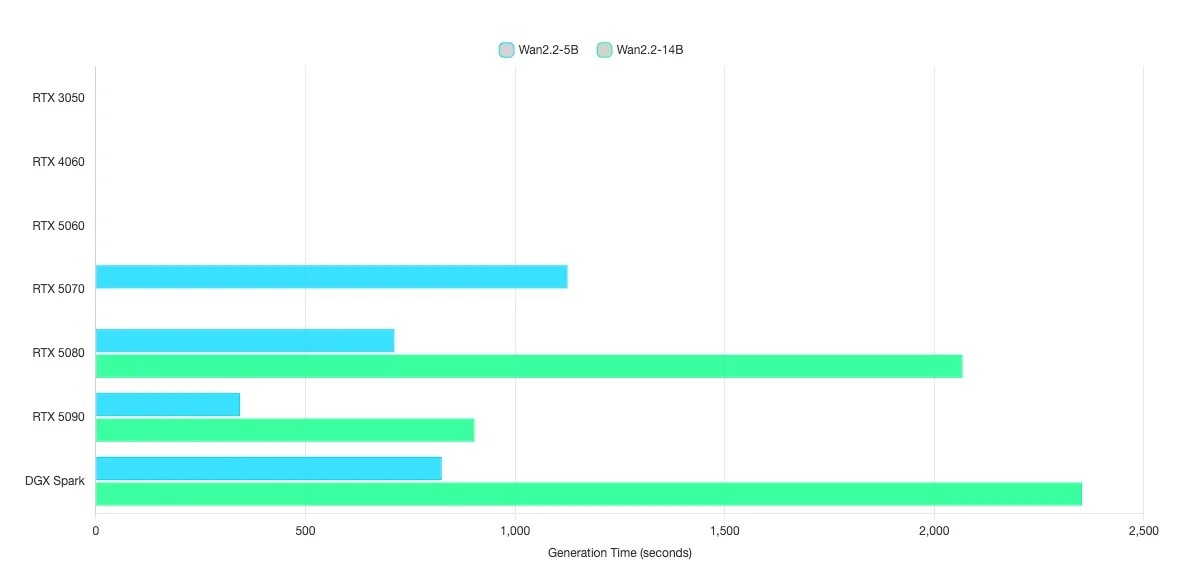
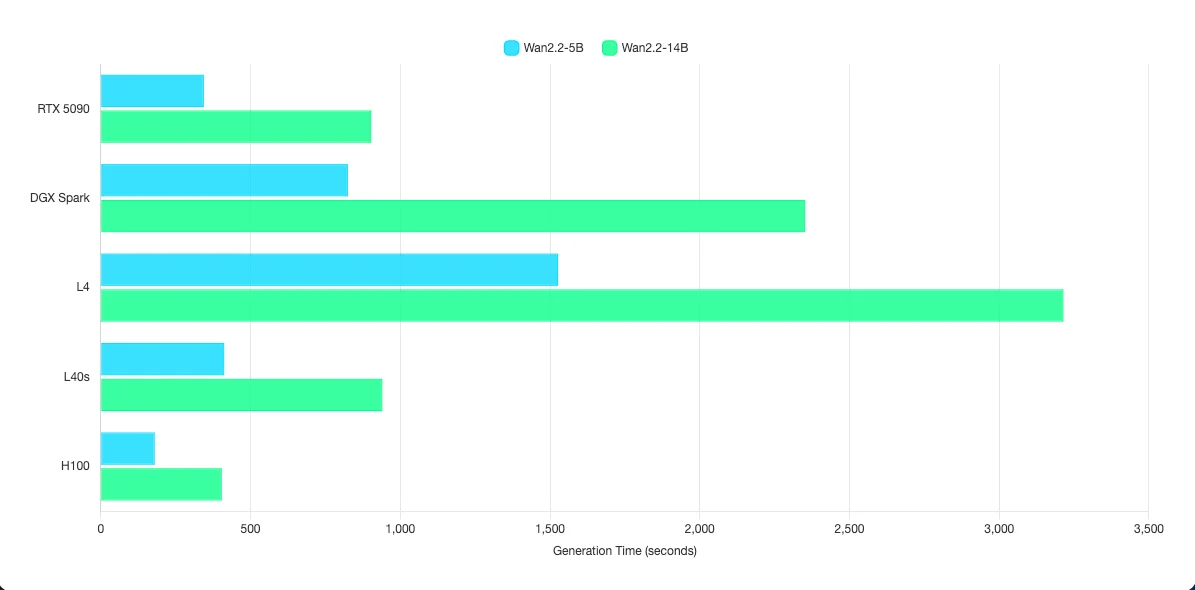
| Wan2.2-5B | Video Gen | N/A2 | N/A2 | N/A2 | 1125 | 712 | 344 | 825 | 1527 | 412 | 180 |
| Wan2.2-14B | Video Gen | N/A2 | N/A2 | N/A2 | N/A2 | 2067 | 903 | 2352 | 3214 | 940 | 404 |
ตัวเลขที่แต่ละ Model ได้ออกมานั้น คือตัวเลขของเวลาที่ใช้ในการประมวลผล 1 วีดิโอในหน่วยของวินาที ค่ายิ่งน้อยยิ่งดี โดยค่านี้จะสื่อถือความเร็วในการประมวลผลรูปภาพ 1 วิดีโอตั้งแต่ต้นจนจบ
การตั้งค่า
- สร้าง Video ที่ความละเอียด 480p เป็นระยะเวลา 5 วินาที
- Model weight ใช้ FP8 และ INT8
- ไม่ใช้เทคนิค Caching หรือ Distillation
N/A2 หมายถึง GPU ดังกล่าวไม่สามารถรัน Model นั้น ๆ ได้ เนื่องจาก VRAM มีไม่เพียงพอ
ตัวอย่างจาก Video Generation (Text-to-Video)
ผลการทดสอบกลุ่ม Audio-to-Text
สำหรับการทดสอบกลุ่มที่ 4 เป็นการรัน AI ที่ตอบโต้กลับมาเป็น Text เท่านั้น
เราสามารถเห็นการใช้งาน AI ในลักษณะดังกล่าวกับ Application เช่น ChatGPT, Gemini เป็นต้น
| Model | Type | RTX 3050 | RTX 4060 | RTX 5060 | RTX 5070 | RTX 5080 | RTX 5090 | DGX Spark | L4 | L40s | H100 |
|---|---|---|---|---|---|---|---|---|---|---|---|
| Typhoon-ASR | Speech to Text | 0.373 | 0.354 | 0.353 | 0.352 | 0.344 | 0.324 | 0.342 | 0.324 | 0.364 | 0.392 |
ตัวเลขที่แต่ละ Model ได้ออกมานั้น คือตัวเลขของเวลาที่ใช้ในการประมวลผล 1 คลิปเสียงในหน่วยของประสิทธิภาพต่อเวลา ค่ายิ่งน้อยยิ่งดี โดยค่านี้จะสื่อถือความเร็วในการประมวลคลิปเสียง 1 คลิปเสียง
ตัวอย่างเช่น
ค่าประสิทธิภาพที่ 0.1
คลิปเสียงยาว 10 วินาที
จะใช้เวลาในการประมวลผล 1 วินาที
หรือ
ค่าประสิทธิภาพที่ 2
คลิปเสียงยาว 10 วินาที
จะใช้เวลาในการประมวลผล 20 วินาที
การตั้งค่า
- คลิปเสียงความยาว 10 วินาที
สรุป
เราสามารถสรุป GPU สำหรับการรัน AI แต่ละกลุ่มได้ดังนี้
1. RTX 3050, RTX 4060, RTX 5060 รัน AI Text-to-Text, Text-to-Image, Audio-to-Text ได้ แต่ไม่สามารถรัน Text-to-Video ได้ โดย RTX 5060 สามารถรัน Text-to-Image ได้ไวกว่า RTX 3050 มากถึง 2 เท่า (422 วินาที vs 192 วินาที)
2. RTX 5070 เป็นตัวเริ่มต้นสำหรับการรัน AI Vision-to-Text และ Text-to-Video โดย Vision-to-Text ได้ควาเร็วมากกว่า RTX 5060 มากถึง 3.7 เท่า (707.7 tok/s vs 189.99 tok/s)
3. RTX 5080 เป็นตัวเลือกขั้นต่ำสำหรับการเริ่มนำไปทำงาน Production โดยได้ Quality ที่สามารถเริ่มใกล้เคียงกับ AI ที่เสียเงิน ไม่ว่าจะเป็นการสามารถใช้งาน Qwen3 VL 8B ซึ่งเพียงพอในการใช้งานทั่วไป, Typhoon-ocr-3b สำหรับการแปลงรูปภาพให้เป็นตัวอักษร และ การสร้างวีดิโอด้วย Wan2.2-14B
4. RTX 5090 เป็นตัวเลือกที่ดีที่สุดสำหรับการใช้งาน Production โดยความเร็วในการประมวลผลทุกโมเดลที่ดีกว่า RTX 5080 มากกว่า 2 เท่าในเกือบทุก Model และยังสามารถรัน AI จาก OpenAI เช่น GPT-OSS-20B ได้แล้ว
5. DGX Spark เป็นตัวเลือกสำหรับ Developer ที่อยากใช้งาน AI ในปัจจุบันและในอนาคตอีก 2 - 3 ปีเป็นอย่างน้อย ข้อดีของ DGX Spark คือ VRAM แชร์รวมกับ RAM คล้ายกับ Apple M Serise ที่มีขนาดใหญ่ถึง 128 GB ซึ่งสามารถรัน AI ขนาดใหญ่ได้ถึง GPT-OSS-120B แต่ข้อควรรู้คือ DGX Spark เกิดมาใช้งานกับ Linux เป็นหลัก เนื่องจาก Chip ประมวลผลเป็น ARM Architecture ทำให้ใช้งาน windows ไม่ได้ ซึ่งน่าจะข้อจำกัดของใหญ่ที่สุดของ DGX Spark สำหรับผู้ใช้งานทั่วไป
6. Enterprise GPU เป็นตัวเลือกที่โดดเด่นกว่าอย่างเห็นได้ชัด เมื่อเทียบกับ RTX โดยเฉพาะ AI ที่ต้องการการประมวลผลอย่างสูงเช่น Video Generate สามารถจบงานได้ไวกว่าถึง 2.2 เท่า และเหนือกว่าอย่างเห็นได้ชัดเมื่อใช้ AI ที่ต้องการรองรับผู้ใช้งานอย่างสูงเช่น LLM, VLM ที่สามารถสร้าง Token ได้สูงกว่าเกือบ 10 เท่าโดยเฉลี่ยอยู่ที่ 7 - 10 เท่าโดยประมาณ
ความแตกต่างของการเลือกซื้อ GPU สำหรับงานทั่วไปและงานประเภท AI
เมื่อพระเอกไม่ใช่ Compute Unit แต่เป็น VRAM ของ GPU เนื่องจาก AI ปัจจุบันมีขนาดใหญ่ระดับ Billion ไปจนถึง Trillion parameters ยิ่งมีขนาดใหญ่ ยิ่งเก่งขึ้นเท่านั้น และส่งผลทำให้ต้องการขนาดของ VRAM ที่มากตามขึ้นไปด้วย
เทียบให้เห็นภาพชัด ๆ VRAM เปรียบเสมือนพื้นที่ในการติดตั้ง AI ถ้ามี VRAM ไม่พอก็ไม่สามารถติดตั้งหรือใช้งาน AI ได้ ต่อให้ Compute Unit จะแรงแค่ไหน แต่ถ้าติดตั้ง AI ไม่ได้ก็ไม่สามารถที่จะรัน AI ได้นั้นเอง
วิธีการคำนวน VRAM ของ GPU สำหรับการใช้งาน AI เบื้องต้นแล้ว เราสามารถคำนวนด้วยสูตรอย่างง่าย ได้แก่
VRAM ที่ต้องการขั้นต่ำ = 4GB + (จำนวน Billion Parameters * 1.5)
VRAM ที่แนะนำ = 4GB + (จำนวน Billion Parameters * 2)
วิธีคำนวนนี้เป็นการคำนวนแบบ Play-safe ที่สุด เนื่องจาก AI ปัจจุบันมีเทคนิคการลดจำนวนความต้องการของ VRAM หลากหลายเทคนิค ซึ่งอาจจะทำให้ความต้องการของ VRAM น้อยลงจากที่แนะนำได้มากถึง 2 - 4 เท่า ขึ้นอยู่กับ AI ตัวนั้น ๆ
เพราะฉะนั้นสูตรดังกล่าวจึงเป็นการเผื่อมากกว่าการคำนวนเพื่อให้ได้ VRAM ออกมาเป๊ะ ๆ แต่ก็เพียงพอสำหรับการเอาไปเป็นค่าสำหรับอ้างอิงในการเลือกรุ่นของ GPU ต่อไป
วิธีสังเกตุจำนวน Billion Parameters มีด้วยกัน 2 วิธีอย่างง่าย
วิธีที่ 1 สังเกตจากชื่อของ AI ตัวนั้น ๆ เช่น
scb10x/typhoon2.5-qwen3-4b AI ตัวนี้มีขนาด 4 Billion Parameters
meta-llama/Llama-3.1-8B AI ตัวนี้มีขนาด 8 Billion Parameters
เป็นต้น
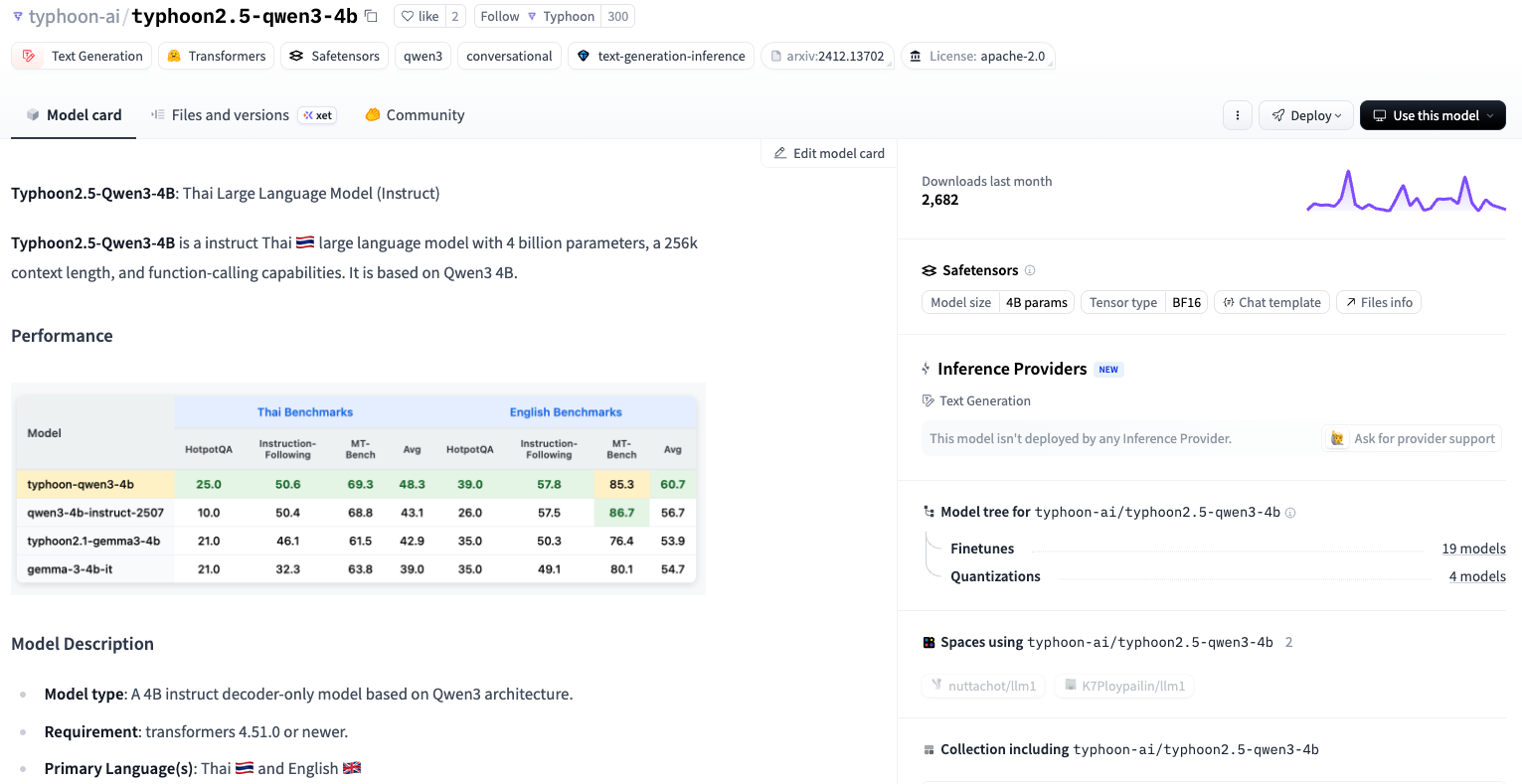
วิธีที่ 2 สังเกตง่าย ๆ จากหัวข้อ Safetensors คำว่า Model Size ได้เลย
อย่างเช่น Model Size จาก Safetensors มีค่าอยู่ที่ 4B หรือ 4 Billion Parameters นั้นเอง
Compute unit เป็นพระรอง แต่ยังสำคัญไม่ต่างจาก VRAM เพราะตั้งแต่ NVIDIA Architecture Turing (RTX 20xx) เป็นต้นมา NVIDIA ได้เพิ่ม Compute unit พิเศษเข้ามา 2 ตัว ได้แก่ RT Core และ Tensor Core
สิ่งที่ส่งผลอย่างมากสำหรับการประมวลผล AI นั้นคือ Tensor Core ได้ถูกออกแบบมาเพื่อประมวลผล Multiplication หรือการคูณกันของ 2 matrix ซึ่งเป็นหัวใจสำคัญของการประมวลผล AI มากกว่า 95%
และเมื่อเทียบ Cuda Core กับ Tensor Core แล้ว Tensor Core ในรุ่นที่ 1 (Turing) จะมีความเร็วในการประมวลผล Floating Point 16 bit เร็วกว่า Cuda Core อยู่ที่ 4 เท่า หรือ Floating Point 8 bit ที่มาใน Tensor Core ในรุ่นที่ 3 (Ada lovelace, Hopper) ถือว่าเป็นการก้าวกระโดดครั้งสำคัญในการส่งผลให้ AI ใช้ทำงานได้เร็วมากขึ้น
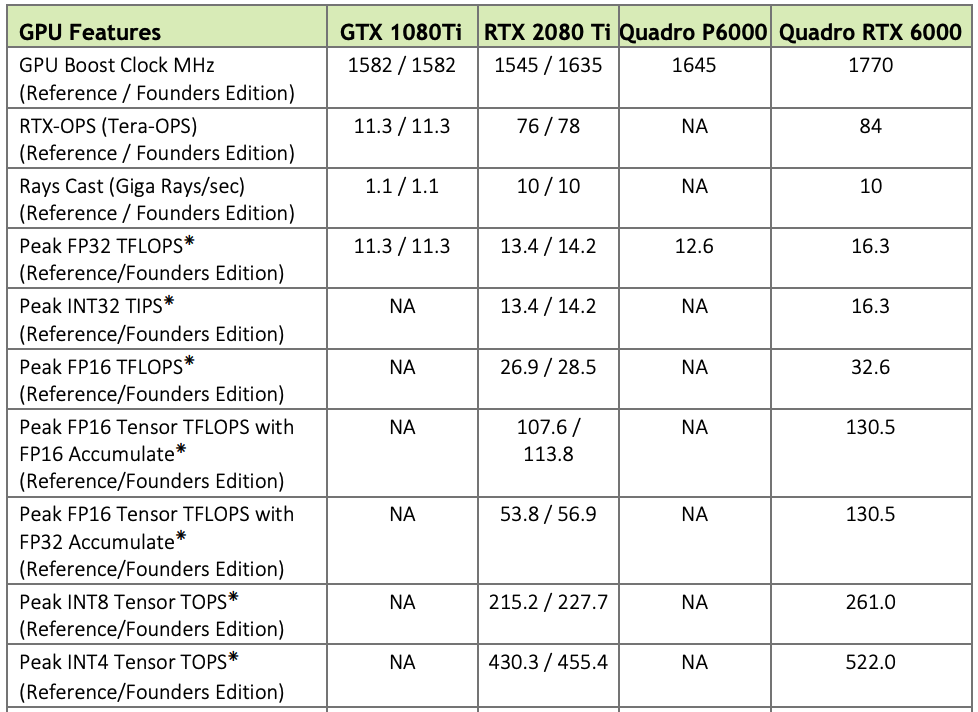
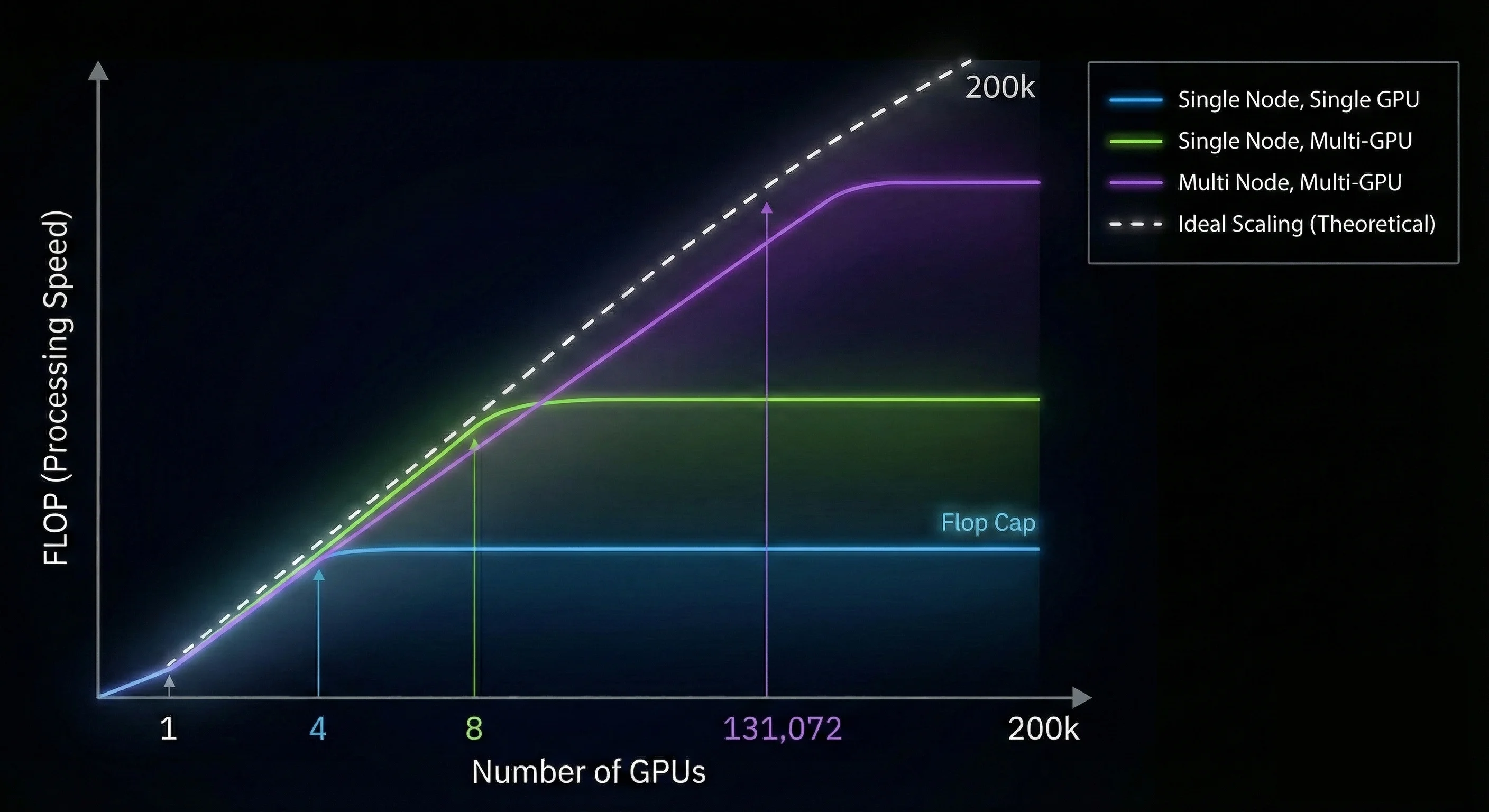
สิ่งสุดท้ายที่สำคัญที่สุดคือ Inter Connect ของ GPU เมื่อใช้งาน GPU ร่วมกันมากกว่า 1 ใบนั้นเอง ถ้า VRAM เปรียบเสมือนพื้นที่ในการติดตั้ง Compute unit เปรียบเสมือนความเร็วในการประมวลผล Inter Connect ของ GPU ก็เปรียบเสมือน Network ระหว่าง GPU นั้นเอง
GPU Inter Connect มีความสำคัญเมื่อใช้งาน GPU ร่วมกันมากกว่า 2 ใบขึ้นไปและจะส่งผลอย่างมากเมื่อใช้งาน GPU ร่วมกันของ GPU Server มากกว่า 2 GPU Server ต่อกัน ซึ่งจะส่งผลกระทบโดยตรงต่อความเร็วในการประมวลผลของ AI ถ้าติดตั้งไม่ถูกวิธีหรือ Config ผิดพลาดไป แทนที่จะส่งผลให้ได้ความเร็วมากขึ้นเป็นเส้นตรง กลับทำให้ความเร็วในการประมวลลดลงหรือไม่เพิ่มขึ้นเลย
GPU Inter Connect เลยเป็นสิ่งที่เป็น Feature สำคัญสำหรับ Enterprise GPU หัวใจสำคัญนั้นคือ NVLink และ NVSwitch ซึ่งสามารถช่วย Scaling ความเร็วในการประมวลผลได้เทียบเท่าความเร็วในทางทฤษฎี การเลือก Enterprise GPU จึงเป็นทางเลือกที่ดีกว่า Consumer GPU สำหรับคนที่กำลังอยากได้ GPU Server ขนาดใหญ่จำนวนตั้งแต่หลัก 50 ใบขึ้นไป
ทิ้งท้าย
ขอขอบคุณผู้ใหญ่ใจดีจากทาง NVIDIA Thailand ที่สนับสนุน Hardware รุ่นต่าง ๆ สำหรับการทดสอบครั้งนี้
ส่วนเสริม
เรารู้ได้ยังไงว่า Performance ที่ทดสอบนั้น ได้มากที่สุดเท่าที่ GPU จะทำได้แล้ว
ทั่วไปแล้ว เราจะสังเกตได้จาก Application ชื่อ nvidia-smi หน้าตาแบบนี้
โดย nvidia-smi จะบอกสิ่งสำคัญอยู่ 3 สิ่ง
1. GPU utilization
2. GPU power consumption
3. GPU VRAM usage
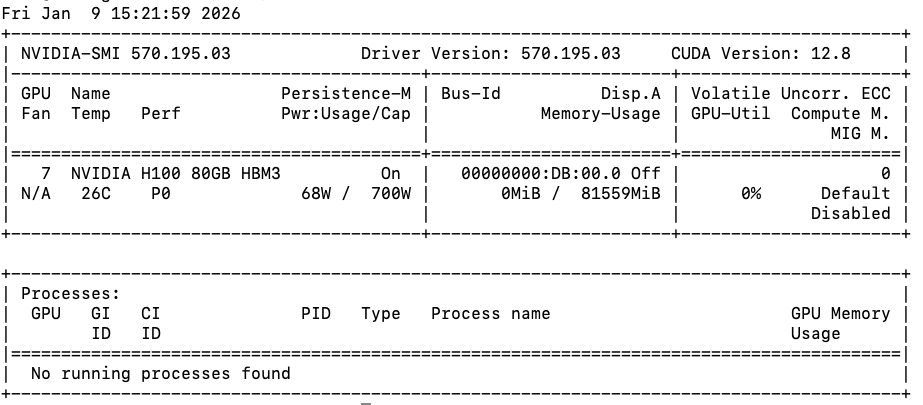
โดยพฤติกรรมของ GPU จะแตกต่างจาก CPU ในเรื่องของการวัด GPU utilization ที่จะไม่ได้ตรงไปตรงมาเหมือนกับ CPU utilization ซะทีเดียว
CPU เราสามารถวัดได้จากการดู CPU utilization เพียงอย่างเดียว ส่วน GPU จำเป็นต้องดูทั้ง GPU utilization และ Power consumption ร่วมด้วย
ตัวอย่างเช่น
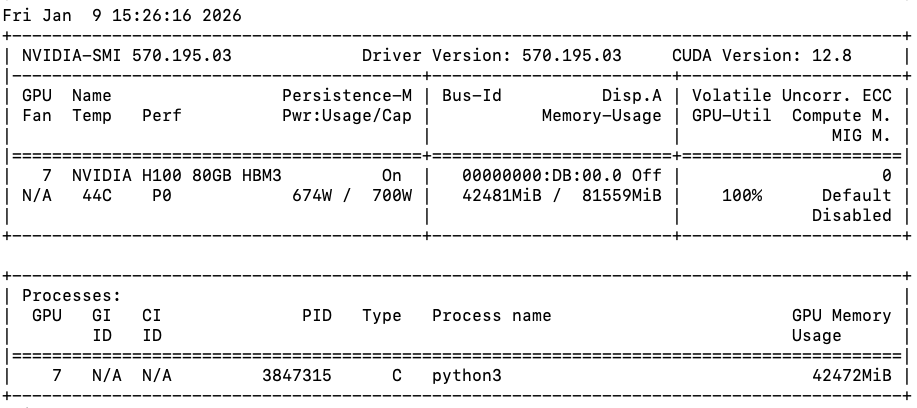
เราสามารถเห็นได้ว่า GPU utilization อยู่ที่ 100% และ Power consumption อยู่ที่ 95%++ ซึ่งตีความได้ว่าเรารีดประสิทธิภาพของ GPU ใบนี้ได้เกือบ 100% แล้วนั้นเอง
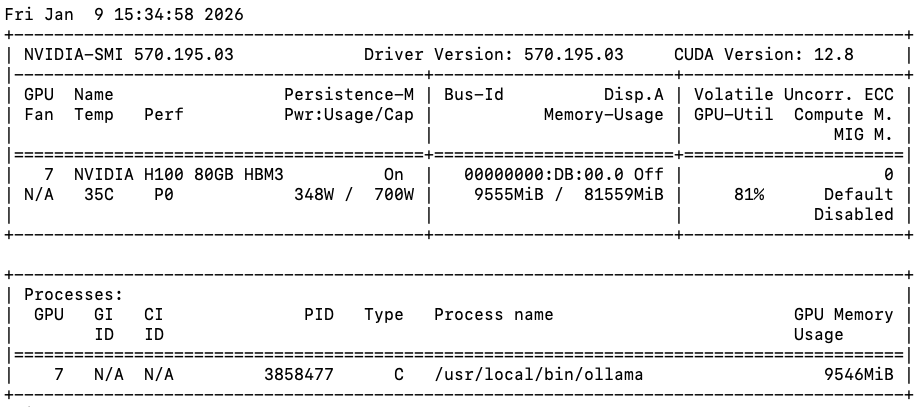 เทียบกับการใช้งานอีกหนึ่งงานเราจะเห็นได้ว่า ใช้ GPU utilization ที่ 81% และ Power consumption อยู่ที่ 50% เท่านั้น ดังนั้นแล้วจึงไม่สามารถวัดการ GPU Performance ด้วยการสังเกตจากแค่ GPU utilization ได้เพียงอย่างเดียว
เทียบกับการใช้งานอีกหนึ่งงานเราจะเห็นได้ว่า ใช้ GPU utilization ที่ 81% และ Power consumption อยู่ที่ 50% เท่านั้น ดังนั้นแล้วจึงไม่สามารถวัดการ GPU Performance ด้วยการสังเกตจากแค่ GPU utilization ได้เพียงอย่างเดียว
vLLM vs Ollama
ทำไมถึงเลือกใช้ vLLM และ WSL Ubuntu (Linux) มากกว่าใช้ Ollama
vLLM ถูกออกแบบมาให้รัน AI ให้รีดประสิทธิภาพของ Hardware ให้ได้สูงที่สุด และเป็น Open Source Library ที่นักวิจัยทั่วโลกใช้เป็นมาตรฐาน กลับกัน Ollama ถูกออกแบบมาเพื่อความง่ายในการรัน AI มากที่สุด โดยเน้นความเข้ากันได้ของ Software มากกว่าการรีดประสิทธิภาพที่สูงที่สุด
GPT-oss-20b Ollama ทดสอบบน RTX 5090 ได้เพียง 120 tok/s แต่ถ้าใช้ vLLM จะได้ tok/s ที่ 1546 tok/s ที่สูงกว่าถึง 13 เท่า ดังนั้นควรเลือกเครื่องมือในการทดสอบให้ถูกต้องและเหมาะสม
Diffuser vs ComfyUI
Diffuser ถูกออกแบบมาคล้ายกับ vLLM ในการรัน AI เพื่อให้รีดประสิทธิภาพของ Hardware ให้ได้สูงที่สุด และสามารถที่จะทดสอบทำซ้ำได้อย่างแม่นยำและเป็นมาตรฐาน กลับกัน ComfyUI ถูกออกแบบมาเพื่อทำให้รัน AI ได้อย่างอิสระ รวมถึงมีเทคนิคการ Optimization เพิ่มเติม ทำให้ใช้ VRAM ลดลง, ประมวลผลเร็วขึ้น หรือติดตั้งง่ายขึ้น ข้อดีคือสามารถทำให้ GPU รัน AI ได้อย่างมีประสิทธิภาพ แต่ข้อเสียคือการทำซ้ำและการควบคุมคุณภาพในการทดสอบทำได้ยาก
Quantization, Caching, Distillation, Off-loading
สำหรับเทคนิคขั้นสูงเหล่านี้ เราจะไม่ได้ใช้แม้แต่เทคนิคเดียว เพื่อให้ผลลัพธ์ของ AI ยังคงครบถ้วนสมบูรณ์ โดยไม่ลดทอนคุณภาพลงแม้แต่น้อย
Source Code
เตรียมเผยแพร่ภายใน Q1/2026
ติดต่อ Float16
- Medium : Float16.cloud
- Facebook : Float16.cloud
- X : Float16.cloud
- Discord : Float16.cloud
- Youtube : Float16.cloud