Self-Host LLM ใช้การ์ดจอใบไหนดี

ทีม Float16 ได้ทำการ Benchmark ตัวเลขออกมาและสรุปอย่างรวดเร็วได้ดังนี้
TL:DR
GPT-OSS 120B
| GPU Model | Card | Max Concurrent | Min Concurrent |
|---|---|---|---|
| H100 | 1 | 32 | 2 |
| H100 | 2 | 128 | 16 |
| B200 | 1 | 64 | 4 |
| B200 | 2 | 256 | 32 |
| PRO 6000 Blackwell | 1 | 24 | 2 |
| PRO 6000 Blackwell | 2 | 96 | 16 |
GPT-OSS 20B
| GPU Model | Card | Max Concurrent | Min Concurrent |
|---|---|---|---|
| H100 | 1 | 128 | 32 |
| H100 | 2 | 384 | 128 |
| B200 | 1 | 256 | 64 |
| B200 | 2 | 768 | 256 |
| PRO 6000 Blackwell | 1 | 96 | 24 |
| PRO 6000 Blackwell | 2 | 288 | 96 |
Qwen3-30B-A3B
| GPU Model | Card | Max Concurrent | Min Concurrent |
|---|---|---|---|
| H100 | 1 | 128 | 24 |
| H100 | 2 | 320 | 48 |
| B200 | 1 | 256 | 48 |
| B200 | 2 | 640 | 96 |
| PRO 6000 Blackwell | 1 | 96 | 24 |
| PRO 6000 Blackwell | 2 | 288 | 96 |
Typhoon2.1-gemma3-12b
| GPU Model | Card | Max Concurrent | Min Concurrent |
|---|---|---|---|
| H100 | 1 | 64 | 16 |
| H100 | 2 | 128 | 32 |
| B200 | 1 | 128 | 32 |
| B200 | 2 | 256 | 64 |
| PRO 6000 Blackwell | 1 | 48 | 12 |
| PRO 6000 Blackwell | 2 | 96 | 24 |
รายละเอียดเต็ม ๆ อยู่ที่ https://docs.google.com/spreadsheets/d/1ITmiYOTslh0x4OjmKaB3yk_sVtQOpJMxLCp0KmEvXMA/edit?usp=sharing
Promote กลุ่ม Open Source AI Community จากทีม Typhoon กลุ่มนี้เลย https://www.facebook.com/groups/748411841298712
คำอธิบายเพิ่มเติมแบบยาว
ตัวแปรต้น, ควบคุมและขอบเขต
สิ่งที่ส่งผลต่อ Concurrents ของ LLM Model มีปัจจัยด้วยกันทั้งหมด 4 ปัจจัย
- ความยาวของ Input (Context windows)
- ความยาวของ Output (Max Generate Token)
- GPU Model รุ่นของ GPU ที่ใช้งาน
- จำนวนของ GPU
ตัวแปรที่เราใช้สำหรับการ Benchmark นี้ได้แก่
- Token Per User ต้องมากกว่า 30 Tokens Per User ถึงนับเป็น 1 Concurrent
- ไม่สนใจ Time To First Token โดยมีเวลานานได้สูงถึง 60 วินาที
- ไม่สนใจ ระยะเวลาในการ Generate output ให้เสร็จสิ้น
ขอบเขต
ตัวเลขดังกล่าวไม่สามารถใช้งานต่อในลักษณะของ Linear Scaling ได้ โดยสามารถทำ Linear Scaling ได้ไม่เกิน 4 Cards มากกว่านั้นจำเป็นต้องเปลี่ยนสูตรในการคำนวนใหม่และการเพิ่มจำนวน Server มากกว่า 1 Node จะไม่สามารถคำนวนแบบ Linear Scaling ได้อีกต่อไป ถ้าต้องการคำนวนมากกว่า 1 Node โปรดติดต่อทีม Float16 เป็นกรณีพิเศษ
การออกแบบ Benchmark
Benchmark นี้เราตั้งใจออกแบบ workload ให้สอดคล้องกับ Use case ปัจจุบันมากขึ้น โดยแบ่ง workload ออกเป็น 3 ประเภทได้แก่
- Chat ทั่วไป
- Web Search Chat หรือ RAG
- Deep Research หรือ Agentic Chat
โดย workload ทั้ง 3 ประเภทนี้จะส่งผลต่อความยาวของ Input ดังนี้
| Workload | ISL (ความยาว Input) | OSL (ความยาว Output) |
|---|---|---|
| Chat | 512 | 1024 |
| Web Search | 8k | 1024 |
| Deep Research | 16k | 1024 |
และเราจะกำหนดให้
Workload Chat เท่ากับ Max Concurrent
Workload Deep Research เท่ากับ Min Concurrent
วิธีการทดสอบ
- ตั้ง Server LLM ขึ้นมา 1 Server ด้วย vllm
- จากนั้นใช้ genai-perf เพื่อทดสอบ
สอนการ Host LLM ด้วยตัวเอง
การทดสอบจะเริ่มจากการส่ง Requests ของแต่ละ Workload โดยมีขนาดของ Requests ที่เท่ากันคือ 300 Requests แต่มี Concurrents ที่ต่างกันตามลำดับ 16, 32, 64, 128
โดย genai-perf ให้ผลลัพธ์ได้อย่างครบถ้วน ไม่ว่าจะเป็น Time To First Token, Inter Token Time, Min Max P99 P90 P75 ซึ่งเราจะนำไปสรุปผลต่อในขั้นถัดไป
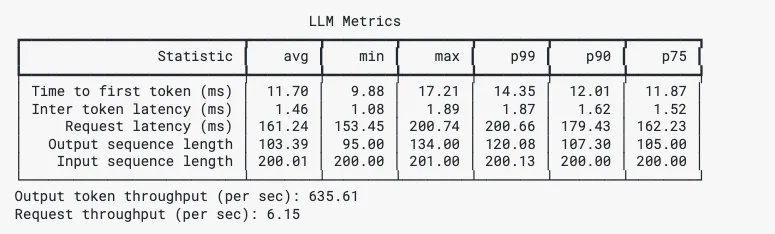
ตัวอย่างผลลัพธ์ของ GenAI-Perf
Model ที่ใช้ทดสอบ
GPT-OSS-120B & GPT-OSS-20B
Qwen3-30B-A3B
Benchmark สำหรับ Qwen3-30B-A3B สามารถนำไปอ้างอิง Model อื่นในตระกูลได้เช่น Qwen3-Coder-30B-A3B เป็นต้น
Typhoon2.1-gemma3-12b
Typhoon เป็น Model สำหรับภาษา Thai - English โดยเฉพาะ สามารถติดตามเพิ่มเติมได้ที่ https://opentyphoon.ai/
สรุปผล
ผลลัพธ์ของการทดสอบเป็นไปได้ด้วยดีและมีปรากฎการณ์บางอย่างระหว่างการทดสอบ เช่น ปรากฎการณ์ Super-Linear และ Non-Linear เกิดขึ้น
ปรากฎการณ์ Super-Linear Scaling
เป็นปรากฎการณ์เมื่อเพิ่ม GPU 2 เท่ากลับได้ Concurrent ที่สูงกว่า 2 เท่า
สาเหตุของปรากฎการณ์ Super-Linear Scaling คือ KV Cache
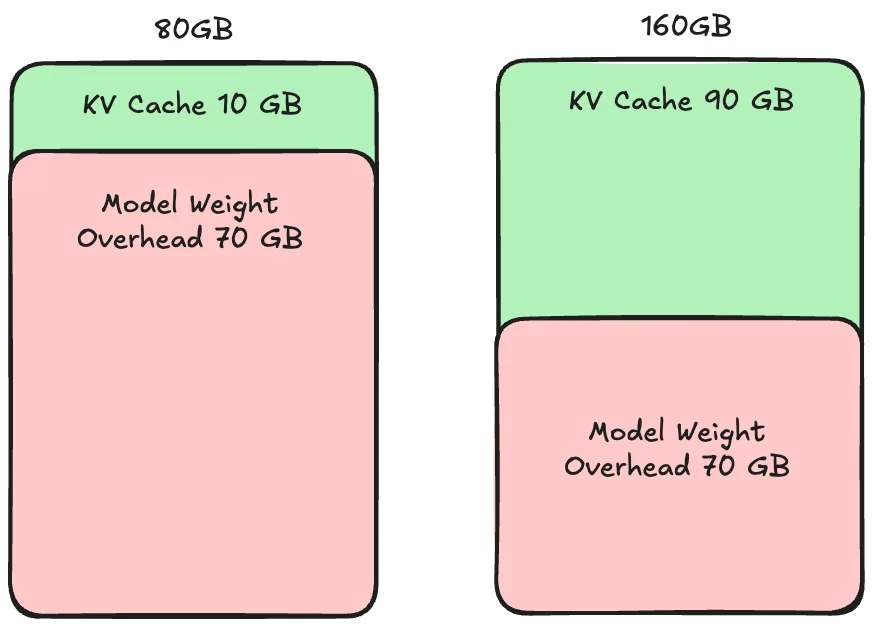
Super-Linear Scaling
KV Cache คือส่วนของ Caching สำหรับการประมวลของแต่ละ Request ซึ่งถ้า KV Cache มีขนาดน้อยกว่า Request จะส่งผลให้ประมวลได้ช้าลง
ซึ่ง Super-Linear Scaling เกิดขึ้นเมื่อ GPU 1 ใบมีพื้นที่ KV Cache น้อยเกินไปสำหรับการประมวลผลพร้อมกันของ Requests ที่เข้ามา ส่งผลให้เกิดคอขวดของ Memory
ดังนั้นการเพิ่ม GPU เข้าไปอีก 1 ใบทำให้ช่วยได้ทั้ง Compute และ Memory ทำให้ประสิทธิภาพที่ได้จากการเพิ่ม GPU ได้มากกว่า 2 เท่าเนื่องจากได้ประโยชน์จากทั้ง Compute และ Memory
ปรากฎการณ์ Non-Linear Scaling
เป็นปรากฎการณ์เมื่อเพิ่ม GPU 2 เท่าหรือมากกว่า 1 Node กลับได้ Conccurent ที่น้อยกว่า 2 เท่าหรืออาจจะน้อยกว่า 1 เท่า
สาเหตุของปรากฎการณ์ Non-Linear Scaling คือ Inter-Network Bandwidth ระหว่าง Node หรือระหว่าง Cards

เปรียบเทียบ High Bandwidth และ Low Bandwidth
Non-Linear Scaling เกิดขึ้นเมื่อต้องเชื่อมต่อ GPU มากกว่า 1 ใบหรือมากกว่า 1 Node ซึ่ง โดยเฉพาะการเชื่อมต่อมากกว่า 1 Node ที่จำเป็นต้องทำ Synchronization ระหว่าง Node เพื่อให้การประมวลผลต่อเนื่องและยิ่งการประมวลผลด้วยความเร็วสูงและจำนวน Node มีจำนวนมาก การทำ Synchronization จำเป็นต้องทำทุก Node เพราะฉะนั้นแล้วถ้า Network Bandwidth และ Speed ช้ากว่าการ Synchronization จะทำให้ประสิทธิภาพถูกจำกัดด้วยการ Synchronization นั้นเอง
ทิ้งท้าย
ขอให้ทุกท่านสนุกกับการใช้งาน GPU ในการ Self-Host LLM และถ้ามีคำถามสามารถเข้ามาถามได้ที่ Discord Float16 หรือ Facebook Messager ของ Float16 ได้ตลอดเวลา
หมายเหตุ
ผลลัพธ์ของ B200 และ PRO 6000 Blackwell เป็นการคำนวนทางทฤษฎีต่อยอดจากผลลัพธ์ของ H100 ซึ่งอาจมีความคลาดเคลื่อนในการทดสอบจริง
ตัวเลขที่นำเสนอ (B200, PRO 6000 Blackwell) เป็นตัวเลขประเมินขั้นต่ำ การทดสอบจริงมีโอกาสอย่างมากที่จะได้ตัวเลขที่สูงกว่าที่นำเสนอไป ทั้งนี้สามารถใช้ตัวเลขเพื่อเป็น Guideline ในการประเมินเบื้องต้นได้
Contact
- Medium : Float16.cloud
- Facebook : Float16.cloud
- X : Float16.cloud
- Discord : Float16.cloud
- Youtube : Float16.cloud
- Email : business[at]float16.cloud