Trích xuất Dữ liệu từ Hình ảnh bằng Gemma3

Để trích xuất dữ liệu từ hình ảnh như hóa đơn, thẻ ID hoặc biểu mẫu giấy, các phương pháp truyền thống thường sử dụng OCR (Optical Character Recognition) kết hợp với quy tắc hoặc regex để trích xuất dữ liệu. Điều này phức tạp và khó khăn khi định dạng dữ liệu thay đổi.
Trên thực tế, chúng ta có một lựa chọn khác: LLM Multimodal có thể "hiểu hình ảnh" và "trả lời câu hỏi" trực tiếp.
Khái niệm
LLM Multimodal có thể xử lý cả văn bản và hình ảnh đồng thời, cho phép chúng ta nhập hình ảnh cùng với prompt như:
Hình ảnh này là hóa đơn nhà hàng. Vui lòng trích xuất dữ liệu thành JSON: tên nhà hàng, ngày, món ăn, tổng số tiền
Ví dụ Code
Model
Lần này chúng ta sẽ thử sử dụng gemma3-12b-vision
Bạn có thể làm theo Getting Started trong README cho bất kỳ ai muốn thử triển khai mô hình
Code
client-gemma3.ts
- Đặt một prompt rõ ràng về hình ảnh này là gì, cần những trường nào với ví dụ, làm gì nếu không tìm thấy và chỉ định rằng nó phải trả về chỉ ở định dạng JSON. Ở đây chúng ta cũng sẽ nói với nó để xem
categoryđể xác định nó là gì. Nếu làinvoice, thì trích xuất các trường chúng ta muốn, nhưng nếu không, hãy cho chúng ta biết nó là gì.
This is an image of a document. Please analyze the document and return a JSON object that strictly follows the schema below:
{
"category": string, // Document category: "invoice", "receipt", or "other-[description]"
"result": object | null // Invoice data if category is "invoice", otherwise null
}
If the document category is "invoice", return the result as:
{
"category": "invoice",
"result": {
"invoice_number": string, // e.g. "INV-2024-00123"
"invoice_date": string, // Date as shown in document (any format: DD/MM/YYYY, MM-DD-YYYY, YYYY-MM-DD, etc.)
"due_date": string | null, // Date as shown in document (any format) or null if not found
"total_amount": number | null, // Final total amount (e.g. 1234.50) in INR
"items": [
{
"description": string, // Name of the product or service
"quantity": number | null,
"unit_price": number | null,
"line_total": number | null
}
]
}
}
If the document category is NOT "invoice", return the result as:
{
"category": "receipt" | "other-[description]",
"result": null
}
DOCUMENT CATEGORY GUIDELINES:
- "invoice": Only tax invoices, billing invoices, commercial invoices
- "receipt": Payment receipts, transaction receipts
- "other-[description]": For any other content, describe what you see after "other-"
Examples: "other-id_card", "other-child_photo", "other-certificate", "other-bill", "other-menu", "other-text_document"
IMPORTANT INSTRUCTIONS:
- Only extract invoice data if the document category is clearly "invoice"
- For receipts, use exactly "receipt" as the category
- For anything else, use "other-" followed by a brief English description of what you see
- For dates, extract them exactly as they appear in the document - do not convert or reformat
- For all non-invoice documents, set result to null
- Do not guess or fabricate values
- Return ONLY the JSON object directly. Do not wrap it in markdown code blocks (\`\`\`json\`\`\`)
- Do not include any explanation, comments, or extra text before or after the JSON
- Your response should start with { and end with }
- The response must be valid JSON that can be parsed directly
- Truyền hình ảnh qua kiểu
image_urltrong nội dung tin nhắn qua lại
const { data } = await axios.post(
`${process.env.BASE_URL}/chat/completions`,
{
model: "gemma3-12b-vision",
messages: [
{
role: "user",
content: [
{
type: "text",
text: prompt,
},
{
type: "image_url",
image_url: { url: `data:image/jpeg;base64,${image}` },
},
],
},
],
},
{
headers: {
Authorization: `Bearer ${process.env.API_KEY}`,
"Content-Type": "application/json",
},
}
);
client-openai.ts
Cho các trường hợp sử dụng các Mô hình khác hỗ trợ OpenAI Completions và Multimodal
Kết quả
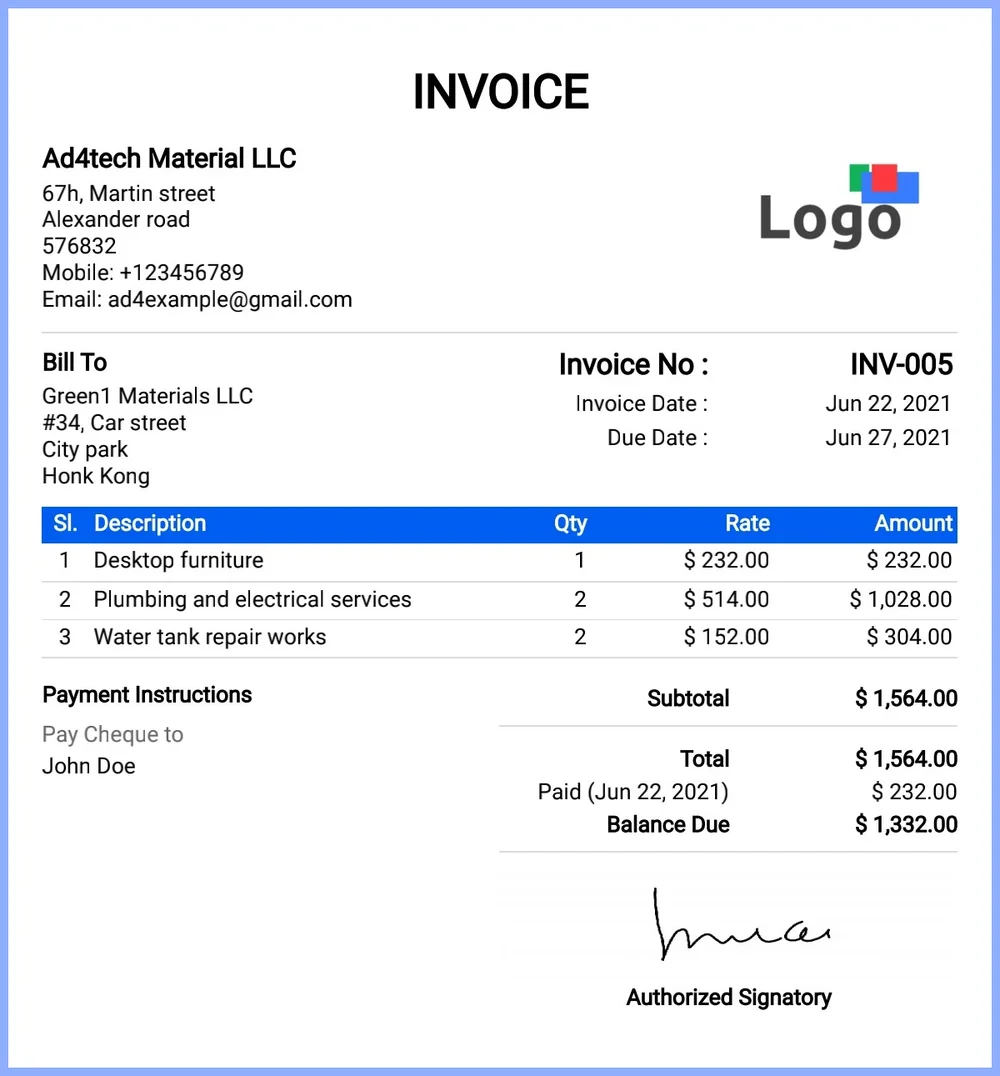
{
"category": "invoice",
"result": {
"invoice_number": "INV-005",
"invoice_date": "Jun 22, 2021",
"due_date": "Jun 27, 2021",
"total_amount": 1564,
"items": [
{
"description": "Desktop furniture",
"quantity": 1,
"unit_price": 232,
"line_total": 232
},
{
"description": "Plumbing and electrical services",
"quantity": 2,
"unit_price": 514,
"line_total": 1028
},
{
"description": "Water tank repair works",
"quantity": 2,
"unit_price": 152,
"line_total": 304
}
]
}
}

{
"category": "invoice",
"result": {
"invoice_number": "100",
"invoice_date": "1/30/23",
"due_date": "1/30/23",
"total_amount": 420,
"items": [
{
"description": "20\" x 30\" hanging frames",
"quantity": 10,
"unit_price": 15,
"line_total": 150
},
{
"description": "5\" x 7\" standing frames",
"quantity": 50,
"unit_price": 5,
"line_total": 250
}
]
}
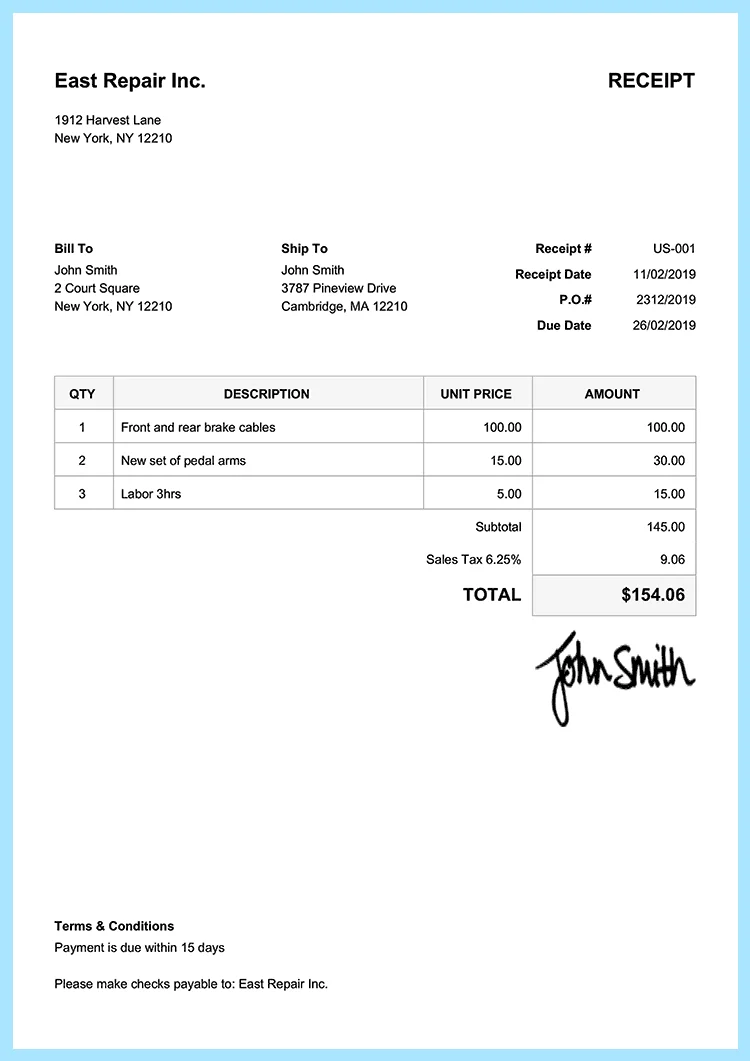
{
"category": "receipt",
"result": null
}
Ưu điểm
- Hoạt động với nhiều định dạng (ngay cả khi bố cục thay đổi)
- Có thể chỉ định dữ liệu mong muốn thông qua prompt
- Không cần viết regex hoặc template dành riêng cho tài liệu
- Có thể thêm điều kiện như nếu là a thì trích xuất b
- Có thể thực hiện phân loại/xác thực
Lưu ý
- Chi phí tương đối cao (tính theo token)
- Độ chính xác phụ thuộc vào prompt và độ rõ nét của hình ảnh
- Nên có fallback hoặc xác thực trong trường hợp mô hình đưa ra câu trả lời sai
So với Phương pháp OCR
- OCR: Chuyển đổi hình ảnh sang văn bản
- OCR Post-processing: Cải thiện văn bản thu được từ OCR để chính xác hơn
- Text Extraction & Cleaning: Trích xuất văn bản quan trọng và làm sạch dữ liệu
- Document Structure Understanding: Hiểu cấu trúc tài liệu (hóa đơn, biên lai, báo cáo phê duyệt)
- Named Entity Recognition (NER): Xác định tên công ty, ngày, số tiền, số tài liệu
Kết luận
Sử dụng LLM Multimodal để trích xuất dữ liệu từ hình ảnh là một cách tiếp cận xuất sắc, đặc biệt khi tài liệu có nhiều trường và chúng ta chỉ muốn trích xuất các trường cụ thể, bố cục có thể không nhất quán hoặc có các điều kiện nhất định để trích xuất dữ liệu. Chúng ta có thể kiểm soát nó thông qua prompt mà không cần xây dựng các hệ thống parsing phức tạp. Điều này có nghĩa là chúng ta không còn cần bám vào ý tưởng rằng loại công việc này chỉ phải sử dụng OCR và sau đó ngồi viết regex hoặc phân tích thêm để trích xuất dữ liệu mà chúng ta thực sự muốn.
Các ví dụ đưa ra là trích xuất dữ liệu đơn giản, nhưng trên thực tế, có nhiều cách tiếp cận khác mà chúng ta có thể thực hiện. Chúng ta có thể thêm các điều kiện nhất định, sử dụng nó cho Phân loại/Xác thực.
Float16
Nền tảng tài nguyên GPU được quản lý cho các nhà phát triển. Trải nghiệm serverless GPU rẻ nhất ở chế độ spot và endpoint GPU nhanh nhất ở chế độ deploy.
Kết nối với chúng tôi:
- Medium : Float16.cloud
- Facebook : Float16.cloud
- X : Float16.cloud
- Discord : Float16.cloud
- Youtube : Float16.cloud