Bạn Nên Sử Dụng GPU Nào Để Self-Host LLM

Đội ngũ Float16 đã đo lường và tổng hợp số liệu nhanh như sau:
TL:DR
GPT-OSS 120B
| Mô hình GPU | Card | Max Concurrent | Min Concurrent |
|---|---|---|---|
| H100 | 1 | 32 | 2 |
| H100 | 2 | 128 | 16 |
| B200 | 1 | 64 | 4 |
| B200 | 2 | 256 | 32 |
| PRO 6000 Blackwell | 1 | 24 | 2 |
| PRO 6000 Blackwell | 2 | 96 | 16 |
GPT-OSS 20B
| Mô hình GPU | Card | Max Concurrent | Min Concurrent |
|---|---|---|---|
| H100 | 1 | 128 | 32 |
| H100 | 2 | 384 | 128 |
| B200 | 1 | 256 | 64 |
| B200 | 2 | 768 | 256 |
| PRO 6000 Blackwell | 1 | 96 | 24 |
| PRO 6000 Blackwell | 2 | 288 | 96 |
Qwen3-30B-A3B
| Mô hình GPU | Card | Max Concurrent | Min Concurrent |
|---|---|---|---|
| H100 | 1 | 128 | 24 |
| H100 | 2 | 320 | 48 |
| B200 | 1 | 256 | 48 |
| B200 | 2 | 640 | 96 |
| PRO 6000 Blackwell | 1 | 96 | 24 |
| PRO 6000 Blackwell | 2 | 288 | 96 |
Typhoon2.1-gemma3-12b
| Mô hình GPU | Card | Max Concurrent | Min Concurrent |
|---|---|---|---|
| H100 | 1 | 64 | 16 |
| H100 | 2 | 128 | 32 |
| B200 | 1 | 128 | 32 |
| B200 | 2 | 256 | 64 |
| PRO 6000 Blackwell | 1 | 48 | 12 |
| PRO 6000 Blackwell | 2 | 96 | 24 |
Chi tiết đầy đủ tại https://docs.google.com/spreadsheets/d/1ITmiYOTslh0x4OjmKaB3yk_sVtQOpJMxLCp0KmEvXMA/edit?usp=sharing
Quảng bá nhóm Open Source AI Community từ đội Typhoon https://www.facebook.com/groups/748411841298712
Giải Thích Chi Tiết
Biến Độc Lập, Kiểm Soát và Phạm Vi
Các yếu tố ảnh hưởng đến LLM Model Concurrents bao gồm 4 yếu tố:
- Độ dài đầu vào (Context windows)
- Độ dài đầu ra (Max Generate Token)
- Mô hình GPU - Mô hình GPU được sử dụng
- Số lượng GPU
Các biến chúng tôi sử dụng cho Benchmark này:
- Token Per User phải lớn hơn 30 Tokens Per User để tính là 1 Concurrent
- Bỏ qua Time To First Token, có thể mất tới 60 giây
- Bỏ qua thời gian để hoàn thành tạo đầu ra
Phạm vi
Các số liệu này không thể được sử dụng cho Linear Scaling. Linear Scaling có thể thực hiện tới tối đa 4 Card. Vượt quá đó, cần công thức tính toán mới, và thêm nhiều hơn 1 Server Node không thể tính toán bằng Linear Scaling nữa. Nếu bạn cần tính toán hơn 1 Node, vui lòng liên hệ đội Float16 cho các trường hợp đặc biệt.
Thiết Kế Benchmark
Benchmark này được thiết kế có chủ ý với khối lượng công việc phù hợp với các trường hợp sử dụng hiện tại. Chúng tôi chia khối lượng công việc thành 3 loại:
- Chat Chung
- Web Search Chat hoặc RAG
- Deep Research hoặc Agentic Chat
3 loại khối lượng công việc này ảnh hưởng đến độ dài đầu vào như sau:
| Khối lượng công việc | ISL (Độ dài đầu vào) | OSL (Độ dài đầu ra) |
|---|---|---|
| Chat | 512 | 1024 |
| Web Search | 8k | 1024 |
| Deep Research | 16k | 1024 |
Và chúng tôi định nghĩa:
Workload Chat bằng Max Concurrent
Workload Deep Research bằng Min Concurrent
Phương Pháp Kiểm Tra
- Thiết lập 1 LLM Server với vllm
- Sau đó sử dụng genai-perf để kiểm tra
Hướng dẫn Self-Hosting LLM
Kiểm tra bắt đầu bằng cách gửi Requests cho mỗi Workload với cùng kích thước Request là 300 Requests nhưng Concurrents khác nhau tuần tự: 16, 32, 64, 128
genai-perf cung cấp kết quả toàn diện bao gồm Time To First Token, Inter Token Time, Min Max P99 P90 P75 mà chúng tôi sẽ tổng hợp trong các bước tiếp theo.
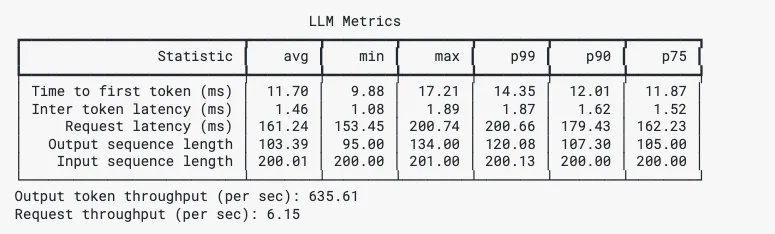
Ví dụ Kết quả GenAI-Perf
Các Mô hình Đã Kiểm Tra
GPT-OSS-120B & GPT-OSS-20B
Qwen3-30B-A3B
Benchmark cho Qwen3-30B-A3B có thể được tham khảo cho các mô hình khác trong họ như Qwen3-Coder-30B-A3B, v.v.
Typhoon2.1-gemma3-12b
Typhoon là Mô hình dành riêng cho ngôn ngữ Thái - Anh. Tìm hiểu thêm tại https://opentyphoon.ai/
Tóm Tắt Kết Quả
Kết quả kiểm tra diễn ra tốt với một số hiện tượng xảy ra trong quá trình kiểm tra, chẳng hạn như hiện tượng Super-Linear và Non-Linear.
Hiện Tượng Super-Linear Scaling
Hiện tượng này xảy ra khi tăng gấp đôi GPU dẫn đến khả năng Concurrent nhiều hơn gấp đôi.
Nguyên nhân của Super-Linear Scaling là KV Cache.
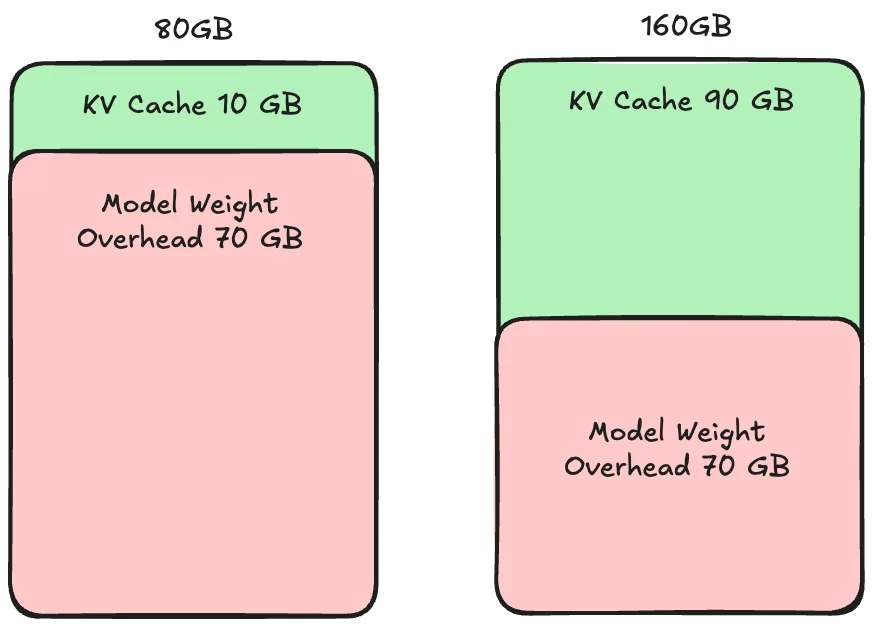
Super-Linear Scaling
KV Cache là phần bộ nhớ đệm để xử lý mỗi Request. Nếu kích thước KV Cache nhỏ hơn Requests, nó sẽ làm chậm quá trình xử lý.
Super-Linear Scaling xảy ra khi 1 GPU có quá ít không gian KV Cache để xử lý đồng thời các Requests đến, gây ra tắc nghẽn Memory.
Do đó, thêm 1 GPU giúp cả Compute và Memory, dẫn đến hiệu suất tăng hơn 2 lần từ việc thêm GPU do lợi ích từ cả Compute và Memory.
Hiện Tượng Non-Linear Scaling
Hiện tượng này xảy ra khi tăng gấp đôi GPU hoặc sử dụng nhiều hơn 1 Node dẫn đến ít hơn gấp đôi Concurrent hoặc có thể ít hơn 1x.
Nguyên nhân của Non-Linear Scaling là Inter-Network Bandwidth giữa các Node hoặc giữa các Card.

So sánh High Bandwidth và Low Bandwidth
Non-Linear Scaling xảy ra khi kết nối nhiều hơn 1 GPU hoặc nhiều hơn 1 Node. Đặc biệt kết nối nhiều hơn 1 Node yêu cầu Synchronization giữa các Node để xử lý liên tục. Càng nhanh và càng nhiều Node, Synchronization phải được thực hiện trên tất cả các Node. Do đó, nếu Network Bandwidth và Speed chậm hơn Synchronization, hiệu suất sẽ bị giới hạn bởi Synchronization đó.
Suy Nghĩ Cuối Cùng
Chúng tôi hy vọng mọi người thích sử dụng GPU để Self-Hosting LLM. Nếu bạn có câu hỏi, bạn có thể hỏi bất cứ lúc nào qua Float16 Discord hoặc Float16 Facebook Messenger.
Ghi Chú
Kết quả B200 và PRO 6000 Blackwell là các tính toán lý thuyết ngoại suy từ kết quả H100, có thể có độ lệch trong kiểm tra thực tế.
Các số liệu được trình bày (B200, PRO 6000 Blackwell) là các số ước tính tối thiểu. Kiểm tra thực tế có khả năng cao nhận được số cao hơn so với trình bày. Các số này có thể được sử dụng làm Hướng dẫn để đánh giá ban đầu.
Liên hệ
- Medium : Float16.cloud
- Facebook : Float16.cloud
- X : Float16.cloud
- Discord : Float16.cloud
- Youtube : Float16.cloud
- Email : business[at]float16.cloud