使用 Gemma3 从图像中提取数据

对于从图像中提取数据,如收据、身份证或纸质表单,传统方法通常使用 OCR(光学字符识别)结合规则或正则表达式来提取数据。当数据格式发生变化时,这既复杂又困难。
实际上,我们还有另一个选择:LLM 多模态 它可以"理解图像"并直接"回答问题"。
概念
多模态 LLM 可以同时处理文本和图像,允许我们输入图像以及提示,例如:
这张图像是一张餐厅收据。请将数据提取为 JSON 格式:餐厅名称、日期、食品项目、总金额
代码示例
模型
在本轮中,我们将尝试使用 gemma3-12b-vision
您可以按照 README 中的入门指南进行操作,适用于任何想自己尝试部署模型的人
代码
client-gemma3.ts
- 设置一个清晰的提示,说明这张图像是什么,需要哪些字段以及示例,如果找不到该怎么办,并指定它必须仅以 JSON 格式返回。在这里,我们还将告诉它查看
category以确定它是什么。如果是invoice,则提取我们想要的字段,但如果不是,则告诉我们它是什么。
This is an image of a document. Please analyze the document and return a JSON object that strictly follows the schema below:
{
"category": string, // Document category: "invoice", "receipt", or "other-[description]"
"result": object | null // Invoice data if category is "invoice", otherwise null
}
If the document category is "invoice", return the result as:
{
"category": "invoice",
"result": {
"invoice_number": string, // e.g. "INV-2024-00123"
"invoice_date": string, // Date as shown in document (any format: DD/MM/YYYY, MM-DD-YYYY, YYYY-MM-DD, etc.)
"due_date": string | null, // Date as shown in document (any format) or null if not found
"total_amount": number | null, // Final total amount (e.g. 1234.50) in INR
"items": [
{
"description": string, // Name of the product or service
"quantity": number | null,
"unit_price": number | null,
"line_total": number | null
}
]
}
}
If the document category is NOT "invoice", return the result as:
{
"category": "receipt" | "other-[description]",
"result": null
}
DOCUMENT CATEGORY GUIDELINES:
- "invoice": Only tax invoices, billing invoices, commercial invoices
- "receipt": Payment receipts, transaction receipts
- "other-[description]": For any other content, describe what you see after "other-"
Examples: "other-id_card", "other-child_photo", "other-certificate", "other-bill", "other-menu", "other-text_document"
IMPORTANT INSTRUCTIONS:
- Only extract invoice data if the document category is clearly "invoice"
- For receipts, use exactly "receipt" as the category
- For anything else, use "other-" followed by a brief English description of what you see
- For dates, extract them exactly as they appear in the document - do not convert or reformat
- For all non-invoice documents, set result to null
- Do not guess or fabricate values
- Return ONLY the JSON object directly. Do not wrap it in markdown code blocks (\`\`\`json\`\`\`)
- Do not include any explanation, comments, or extra text before or after the JSON
- Your response should start with { and end with }
- The response must be valid JSON that can be parsed directly
- 通过
image_url类型在内容消息中来回传递图像
const { data } = await axios.post(
`${process.env.BASE_URL}/chat/completions`,
{
model: "gemma3-12b-vision",
messages: [
{
role: "user",
content: [
{
type: "text",
text: prompt,
},
{
type: "image_url",
image_url: { url: `data:image/jpeg;base64,${image}` },
},
],
},
],
},
{
headers: {
Authorization: `Bearer ${process.env.API_KEY}`,
"Content-Type": "application/json",
},
}
);
client-openai.ts
适用于使用支持 OpenAI Completions 和 Multimodal 的其他模型的情况
结果
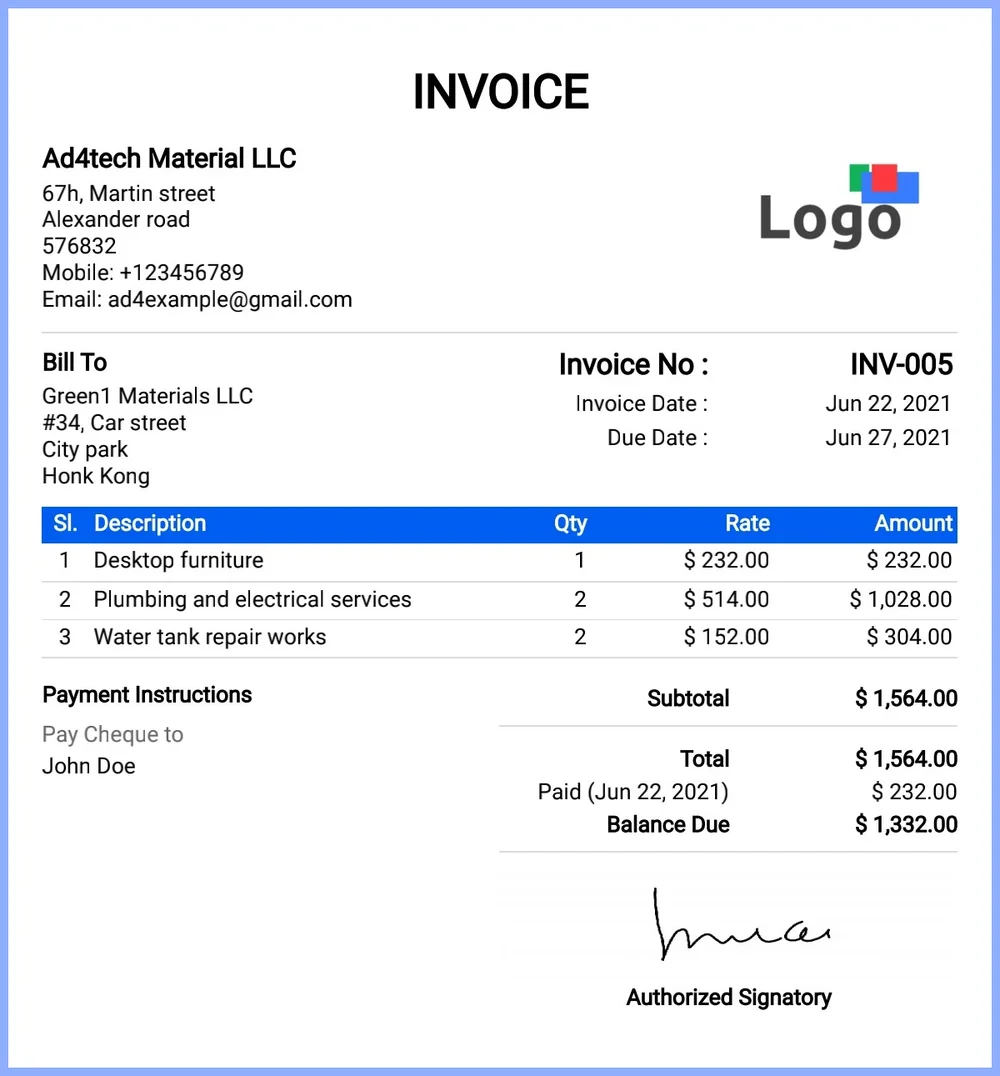
{
"category": "invoice",
"result": {
"invoice_number": "INV-005",
"invoice_date": "Jun 22, 2021",
"due_date": "Jun 27, 2021",
"total_amount": 1564,
"items": [
{
"description": "Desktop furniture",
"quantity": 1,
"unit_price": 232,
"line_total": 232
},
{
"description": "Plumbing and electrical services",
"quantity": 2,
"unit_price": 514,
"line_total": 1028
},
{
"description": "Water tank repair works",
"quantity": 2,
"unit_price": 152,
"line_total": 304
}
]
}
}

{
"category": "invoice",
"result": {
"invoice_number": "100",
"invoice_date": "1/30/23",
"due_date": "1/30/23",
"total_amount": 420,
"items": [
{
"description": "20\" x 30\" hanging frames",
"quantity": 10,
"unit_price": 15,
"line_total": 150
},
{
"description": "5\" x 7\" standing frames",
"quantity": 50,
"unit_price": 5,
"line_total": 250
}
]
}
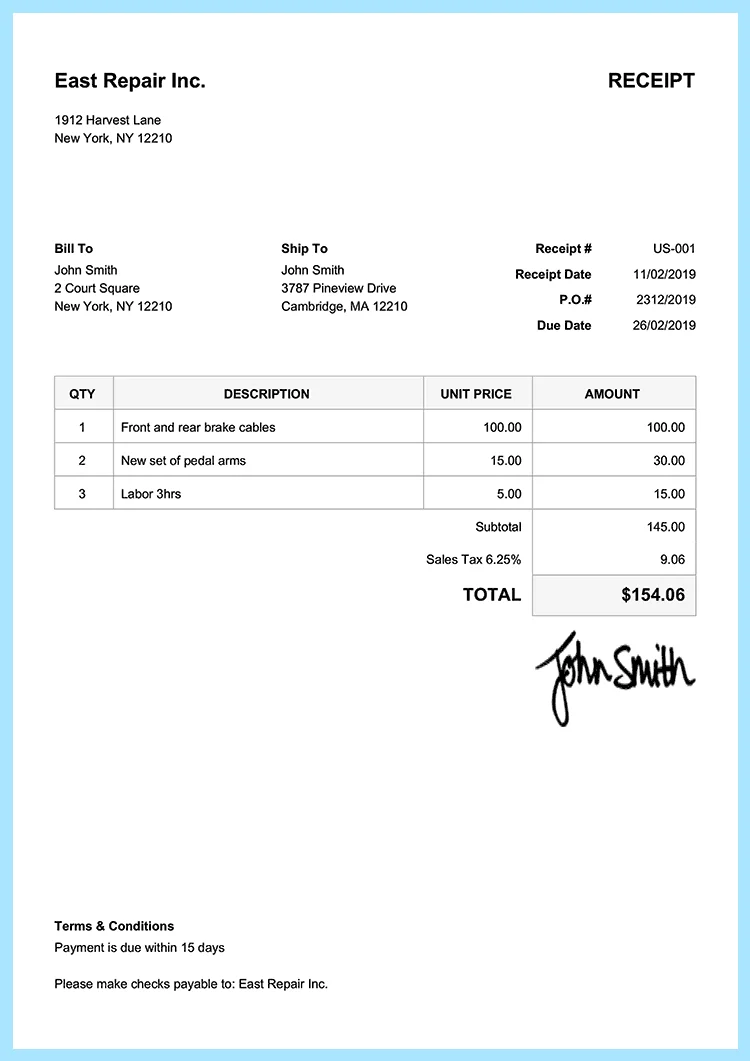
{
"category": "receipt",
"result": null
}
优势
- 适用于多种格式(即使布局发生变化)
- 可以通过提示指定所需的数据
- 无需编写正则表达式或特定于文档的模板
- 可以添加条件,例如如果是 a 则提取 b
- 可以执行分类/验证
注意事项
- 相对较高的成本(按 token 计费)
- 准确性取决于提示和图像清晰度
- 应该有后备或验证,以防模型给出错误答案
与 OCR 方法相比
- OCR:将图像转换为文本
- OCR 后处理:改进从 OCR 获得的文本以使其更准确
- 文本提取和清理:提取重要文本并清理数据
- 文档结构理解:理解文档结构(收据、发票、审批报告)
- 命名实体识别(NER):识别公司名称、日期、金额、文档编号
结论
使用多模态 LLM 从图像中提取数据是一个绝佳的方法,特别是当文档有许多字段而我们只想提取特定字段时,布局可能不一致,或者数据提取有某些条件。我们可以通过提示来控制它,而无需构建复杂的解析系统。这意味着我们不再需要坚持这类工作必须只使用 OCR 然后坐下来编写正则表达式或进一步分析以提取我们真正想要的数据的想法。
给出的示例是简单的数据提取,但实际上,我们可以采取许多其他方法。我们可以添加某些条件,将其用于分类/验证。
Float16
为开发者提供的托管 GPU 资源平台。在 spot 模式下体验最便宜的无服务器 GPU,在 deploy 模式下体验最快的 GPU 端点。
与我们联系:
- Medium : Float16.cloud
- Facebook : Float16.cloud
- X : Float16.cloud
- Discord : Float16.cloud
- Youtube : Float16.cloud