应该使用哪个 GPU 来自托管 LLM

Float16 团队已经对数字进行了基准测试,并快速总结如下:
TL:DR
GPT-OSS 120B
| GPU 型号 | 卡 | 最大并发 | 最小并发 |
|---|---|---|---|
| H100 | 1 | 32 | 2 |
| H100 | 2 | 128 | 16 |
| B200 | 1 | 64 | 4 |
| B200 | 2 | 256 | 32 |
| PRO 6000 Blackwell | 1 | 24 | 2 |
| PRO 6000 Blackwell | 2 | 96 | 16 |
GPT-OSS 20B
| GPU 型号 | 卡 | 最大并发 | 最小并发 |
|---|---|---|---|
| H100 | 1 | 128 | 32 |
| H100 | 2 | 384 | 128 |
| B200 | 1 | 256 | 64 |
| B200 | 2 | 768 | 256 |
| PRO 6000 Blackwell | 1 | 96 | 24 |
| PRO 6000 Blackwell | 2 | 288 | 96 |
Qwen3-30B-A3B
| GPU 型号 | 卡 | 最大并发 | 最小并发 |
|---|---|---|---|
| H100 | 1 | 128 | 24 |
| H100 | 2 | 320 | 48 |
| B200 | 1 | 256 | 48 |
| B200 | 2 | 640 | 96 |
| PRO 6000 Blackwell | 1 | 96 | 24 |
| PRO 6000 Blackwell | 2 | 288 | 96 |
Typhoon2.1-gemma3-12b
| GPU 型号 | 卡 | 最大并发 | 最小并发 |
|---|---|---|---|
| H100 | 1 | 64 | 16 |
| H100 | 2 | 128 | 32 |
| B200 | 1 | 128 | 32 |
| B200 | 2 | 256 | 64 |
| PRO 6000 Blackwell | 1 | 48 | 12 |
| PRO 6000 Blackwell | 2 | 96 | 24 |
完整详情请访问 https://docs.google.com/spreadsheets/d/1ITmiYOTslh0x4OjmKaB3yk_sVtQOpJMxLCp0KmEvXMA/edit?usp=sharing
推广来自 Typhoon 团队的开源 AI 社区群组 https://www.facebook.com/groups/748411841298712
详细说明
自变量、控制量和范围变量
影响 LLM 模型并发的因素包括 4 个因素:
- 输入长度(上下文窗口)
- 输出长度(最大生成 Token)
- GPU 型号 - 使用的 GPU 型号
- GPU 数量
我们用于此基准测试的变量:
- 每个用户的 Token 必须超过 30 个 Token 才能计为 1 个并发
- 忽略首个 Token 时间,可能需要长达 60 秒
- 忽略完成输出生成的持续时间
范围
这些数字不能用于线性缩放。线性缩放最多可以使用 4 张卡。超过这个数量,需要新的计算公式,并且添加超过 1 个服务器节点不能再用线性缩放计算。如果您需要计算超过 1 个节点,请联系 Float16 团队处理特殊情况。
基准测试设计
此基准测试故意设计为与当前用例一致的工作负载。我们将工作负载分为 3 种类型:
- 一般聊天
- 网络搜索聊天或 RAG
- 深度研究或代理聊天
这 3 种工作负载类型影响输入长度如下:
| 工作负载 | ISL(输入长度) | OSL(输出长度) |
|---|---|---|
| 聊天 | 512 | 1024 |
| 网络搜索 | 8k | 1024 |
| 深度研究 | 16k | 1024 |
我们定义:
工作负载聊天等于最大并发
工作负载深度研究等于最小并发
测试方法
- 使用 vllm 设置 1 个 LLM 服务器
- 然后使用 genai-perf 进行测试
自托管 LLM 教程
测试首先为每个工作负载发送相同请求大小为 300 个请求的请求,但不同的并发依次为:16、32、64、128
genai-perf 提供全面的结果,包括首个 Token 时间、Token 间时间、Min Max P99 P90 P75,我们将在后续步骤中总结。
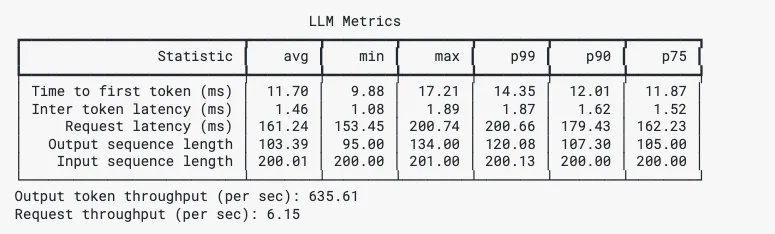
GenAI-Perf 结果示例
测试的模型
GPT-OSS-120B & GPT-OSS-20B
Qwen3-30B-A3B
Qwen3-30B-A3B 的基准测试可以参考该系列中的其他模型,如 Qwen3-Coder-30B-A3B 等。
Typhoon2.1-gemma3-12b
Typhoon 是专门针对泰语 - 英语的模型。了解更多信息请访问 https://opentyphoon.ai/
结果总结
测试结果进展顺利,测试期间发生了一些现象,例如超线性和非线性现象。
超线性缩放现象
当 GPU 翻倍时,并发容量超过两倍,就会发生这种现象。
超线性缩放的原因是 KV Cache。
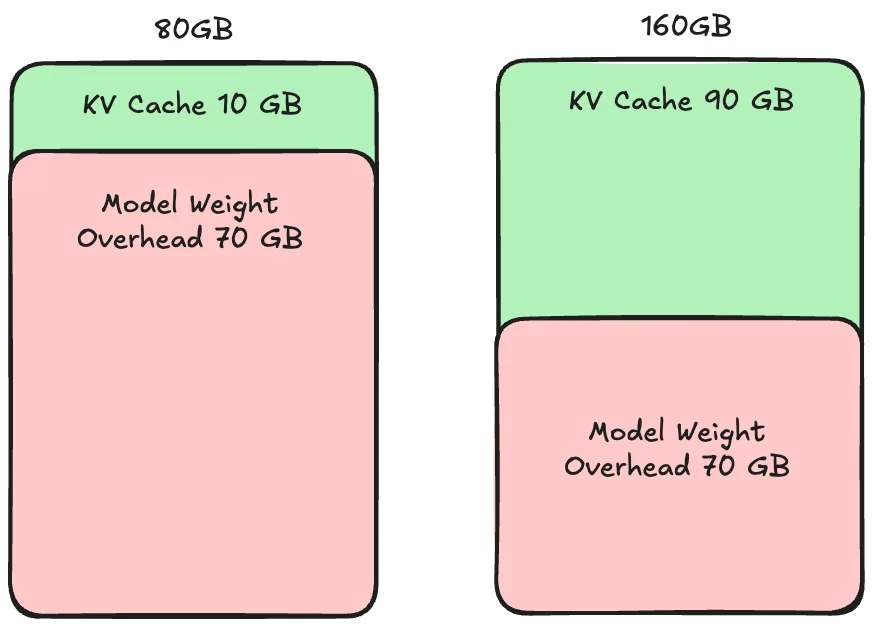
超线性缩放
KV Cache 是处理每个请求的缓存部分。如果 KV Cache 大小小于请求,它将减慢处理速度。
当 1 个 GPU 的 KV Cache 空间太小,无法并发处理传入的请求,导致内存瓶颈时,就会发生超线性缩放。
因此,添加 1 个额外的 GPU 有助于计算和内存,从而由于计算和内存的好处而导致添加 GPU 的性能提升超过 2 倍。
非线性缩放现象
当 GPU 翻倍或使用超过 1 个节点时,并发少于两倍或可能少于 1 倍时,就会发生这种现象。
非线性缩放的原因是节点之间或卡之间的网络带宽。

比较高带宽和低带宽
当连接超过 1 个 GPU 或超过 1 个节点时,就会发生非线性缩放。特别是连接超过 1 个节点需要节点之间的同步以进行连续处理。节点越快越多,同步必须在所有节点上完成。因此,如果网络带宽和速度比同步慢,性能将受到该同步的限制。
最后的想法
我们希望每个人都喜欢使用 GPU 进行自托管 LLM。如果您有问题,可以随时通过 Float16 Discord 或 Float16 Facebook Messenger 询问。
注意事项
B200 和 PRO 6000 Blackwell 的结果是从 H100 结果推断的理论计算,在实际测试中可能会有偏差。
呈现的数字(B200、PRO 6000 Blackwell)是最小估计数字。实际测试很有可能获得比呈现的数字更高的数字。这些数字可以用作初步评估的指南。
联系方式
- Medium : Float16.cloud
- Facebook : Float16.cloud
- X : Float16.cloud
- Discord : Float16.cloud
- Youtube : Float16.cloud
- Email : business[at]float16.cloud