Get compute in under a second, with containers preloaded and ready to run. — no cold starts, no waiting, and no infrastructure to manage. Everything is preloaded for AI and Python development.
No Dockerfiles, no launch scripts, no DevOps overhead. Float16 provisions and configures high-performance GPU infra so you can focus on writing code, not managing hardware.
Train, fine-tune, or batch process on affordable spot GPUs — with the same seamless interface and per-second billing. Scale AI workloads efficiently without blowing your budget.
Use Cases
Serve open-source LLMs via llamacpp in seconds
Provision a high-performance LLM server from a single CLI command — no containers, no cold start
Production-ready HTTPS endpoint
Expose your model as a secure HTTP endpoint immediately. Plug into frontends or APIs without writing infra code.
Run any GGUF-based model
Deploy llama.cpp-compatible models like Qwen, LLaMA, or Gemma. Full control over quantization, context size, and system prompts.
Sub-second latency, no cold starts
Containers remain warm. All requests are served with minimal overhead, even after idle.

Finetune and Train with Spot GPUs, No Infra Work
Execute training pipelines on ephemeral GPU instances using your existing Python codebase.
Spot-optimized scheduling
Backed by autoscaling infra. Jobs are scheduled on available spot GPUs with second-level billing — optimized for throughput and cost.
Native Python, no containerization
Bring your train.py. No Dockerfiles or image builds required — just code execution in isolated containers.
Zero setup environment
System handles CUDA drivers, Python envs, and mounting — just specify the compute size and start the run.
Features of Serverless GPU
Run and deploy your AI workloads instantly with our serverless, containerized infrastructure
Native Python execution on H100
Run .py scripts directly on NVIDIA H100 without building containers or configuring runtimes. Just upload your code and launch — all execution is containerized and GPU-isolated.
Full execution trace & logging
Access real-time logs, view job history, and inspect request-level metrics: task counts, request frequency, and execution duration over time.
Web & CLI-integrated file I/O
Upload/download files via CLI or web UI. All files are mounted into the container at runtime. Supports local files and remote S3 buckets out of the box.
Example-powered onboarding
Deploy with confidence using real-world examples from the Float16 team and community — from model inference to batched training loops.
CLI-first, Web-enabled
Manage everything from the command line, or monitor jobs from the dashboard — both interfaces are tightly integrated with the same backend.
Flexible pricing modes
Run workloads on-demand for short bursts, or switch to spot pricing to optimize long-running jobs like training and finetuning.
Ready to accelerate your AI development? Start deploying your models on H100 GPUs in minutes.
Serverless GPUs withTrue Pay-Per-Use Pricing
Start instantly with per-second billing on H100 GPUs and pay only for what you use — no setup, no idle costs. Whether you're deploying LLMs or running batch training jobs, our pricing is designed to scale with your workload.
Price
GPU Types
On-demand
Spot
H100
$0.006 / sec
$0.0012 / sec
Storage
Free
CPU & Memory
included
Certifications Achieved
We are pleased to announce that we have successfully achieved both SOC 2 Type I and ISO 29110 certifications. For more details, Please visit our Security page.


More Ways to Build with Float16
Beyond serverless GPUs, Float16 includes services that help you deploy, scale, and optimize AI models faster — with no setup, no rate limits, and full developer control.
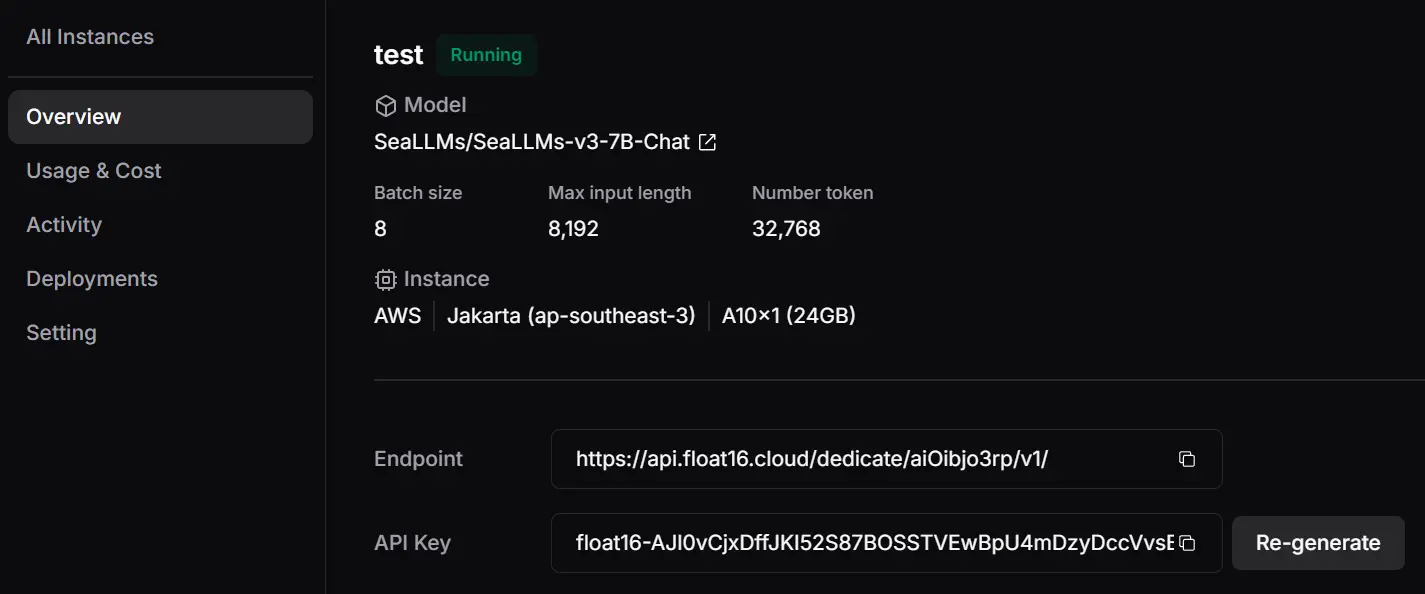
One-Click LLM Deployment
Deploy open-source LLMs like LLaMA, Qwen, or Gemma directly from Hugging Face in seconds. Get a production-ready HTTPS endpoint with zero setup, no rate limits, and cost-effective hourly pricing. Our optimized inference stack includes INT8/FP8 quantization, context caching, and dynamic batching — cutting deployment time by up to 40× and reducing costs by as much as 80%.
LLM as a Service
Deliver production-grade AI with dedicated, always-on LLM endpoints. Choose from a curated set of open-source models fine-tuned for SEA languages and tasks like Text-to-SQL. Our annual plan gives you unlimited token usage, fixed billing, and seamless integration with frameworks like Langchain — optimized for low-latency, efficient inference at scale.
Explore Our Resources
Quantize
Quantize.Float16 is a web-based tool designed to help developers compare the inference speed of LLMs using different quantization techniques and KV cache settings.
Chatbot
Start a conversation with our chatbot, which supports multiple models.
Text2SQL
Effortlessly convert text to SQL queries, enhancing database interactions and streamlining data analysis with high accuracy and efficiency.