Deploy Models Made Easy
Deploy models on dedicated and secure infrastructure without dealing with containers and GPUs
- Streamlined Deployment Process.
- Transform a Hugging Face AI models into production-ready APIs with just a few clicks.
- Optimized Performance.
- Maximize efficiency with automatic performance optimization based on your chosen hardware configuration.
- Cost-Effective Solution.
- Pay only for the compute resources you use, with our fully-managed inference solution.
- Secure Endpoints.
- Protect your deployed models with API key authentication, ensuring authorized access only.
How To Use
Deploy models for production in a few simple steps
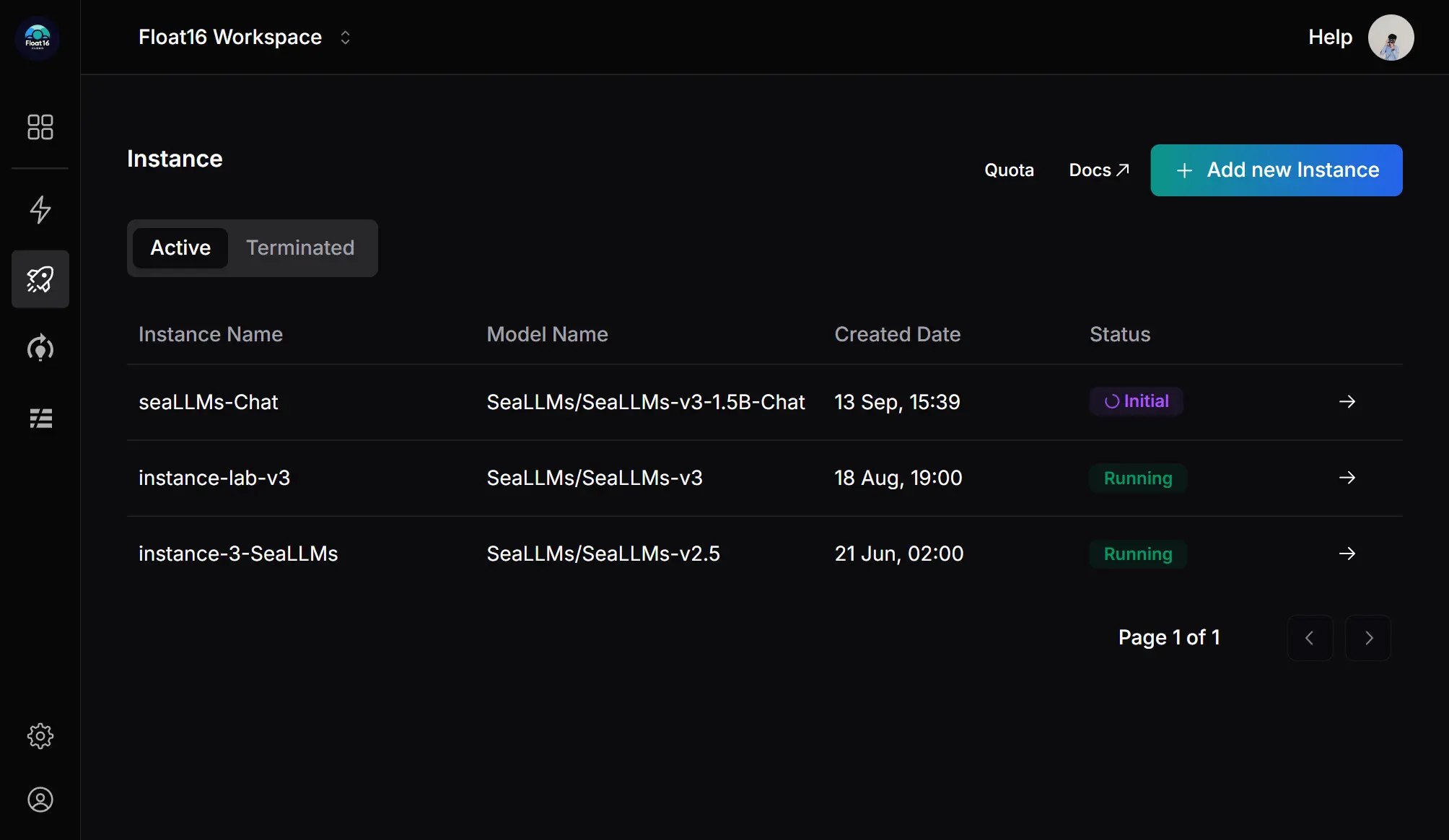
1. Paste your model link
Select the model from HuggingFace and paste the model repository link. You can deploy LLMs based on models like Llama and Gemma, as well as code completion models such as Qwen.
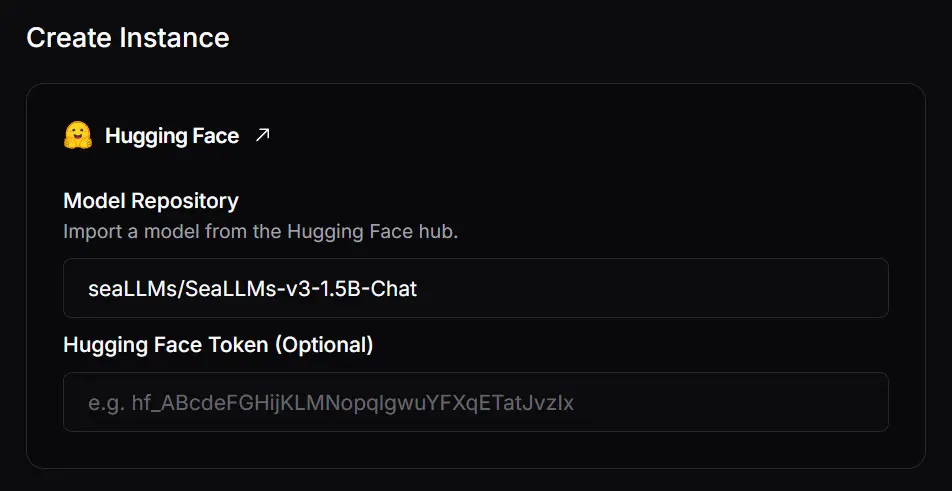
2. Configure your instance
Choose your cloud provider, region, GPU specifications, and optimization techniques. We offer GPUs ranging from L4 to H200. Currently, you can select from over 5 regions, including North America and Asia Pacific.
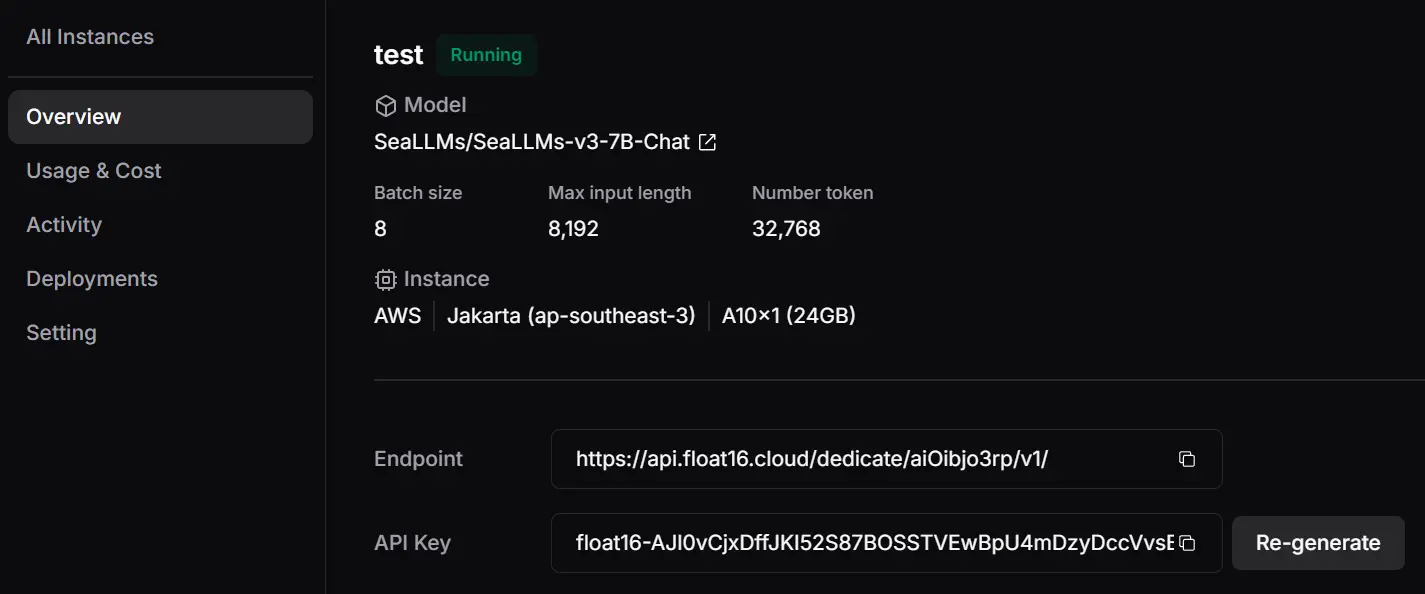
3. Instance Created
Click "Start Deploy" and your new endpoint along with the API key will be ready in a couple of minutes. You can regenerate the API key if needed. Easily monitor activity logs, usage, and costs, and quickly test your model using the chat playground in your instance.
Pricing
Self-Serve
- Pay for what you use, per minute
- Starting as low as $1.2/hour
- Email support
GPU instances
| Provider | Architecture | GPU Memory |
|---|---|---|
| AWS | L4x1 | 24GB |
| AWS | L4x4 | 96GB |
| AWS | A10x1 | 24GB |
| AWS | A10x4 | 96GB |
| AWS | L40sx1 | 48GB |
| AWS | L40sx4 | 192GB |
| Siam AI | H100x1 | 80GB |
| Siam AI | H200x1 | 80GB |