Nvidia GPU 驱动程序设置:AI 开发者的基本步骤

在这个 AI 繁荣的时代,LLM 可能是每个公司都在谈论的东西。许多地方希望 LLM 解决方案在他们的公司中发挥更大的作用,无论是创建聊天机器人、RAG 等。随之而来的是,这些解决方案需要在公司的基础设施中,无论是本地部署还是云提供商,基于数据不应发送到外部 LLM 提供商(如 OpenAI)进行处理的要求。
因此,像我们这样的基础设施人员的新任务将是提供 GPU 机器。然而,获得机器后,仍然有许多事情需要配置,例如安装驱动程序和其他工具。在本文中,我们将介绍基本的机器准备方法,以确保我们创建的 GPU 实例尽可能准备就绪。
我首先要说的是,我们主要使用的 GPU 来自 Nvidia,这是目前用户最多的市场领导者之一。所以所有内容都将使用 Nvidia 作为叙述者。准备好了吗?让我们开始吧!!
安装驱动程序
安装 Nvidia GPU 驱动程序并不像您想象的那么困难或复杂。我们可以遵循 Nvidia 的文档,但我们需要调整一些参数以匹配我们选择的操作系统和 CPU 架构。在本文中,我们可能不会涵盖文档中列出的每个主题,但我们将教授基本的安装方法,以允许 GPU 使用。
Nvidia 驱动程序安装文档
1. 准备所需参数
从 Supported Linux Distributions 表中,它告诉我们哪些 Linux 版本支持驱动程序安装。
我们需要注意的 3 个参数 以供下一步使用:
- $distro
- $arch
- $arch_ext
假设我们在 x86 机器上使用 Linux Ubuntu 22.04 LTS。当我们比较表中的值时:
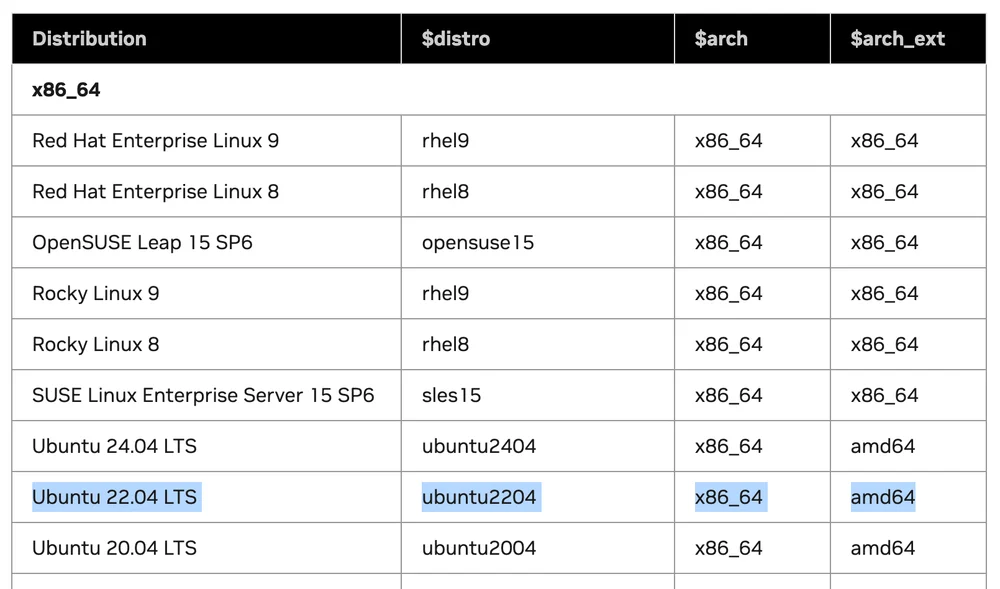
值将是: $distro = ubuntu2204 $arch = x86_64 $arch_ext = amd64
2. 根据 Linux 发行版选择安装指南
此步骤是根据我们的操作系统选择驱动程序安装方法。从我选择 Ubuntu 的示例中,我们将查看解释 Ubuntu 安装方法的第 10 节。

我们需要做的是:
- 遵循所有预安装步骤
- 安装内核头文件和开发包
sudo apt install linux-headers-$(uname -r)
- 在 Local Repository 或 Network Repository 之间选择安装方法。我将选择 Network Repository。
在 URL https://developer.download.nvidia.com/compute/cuda/repos/$distro/$arch/cuda-keyring_1.1-1_all.deb 中
用表中的值替换 $distro 和 $arch
wget https://developer.download.nvidia.com/compute/cuda/repos/ubuntu2204/x86_64/cuda-keyring_1.1-1_all.deb
sudo dpkg -i cuda-keyring_1.1-1_all.deb
sudo apt update
安装新的 cuda-keyring 包
- 安装驱动程序
sudo apt install nvidia-open
完成此步骤后,我们将在机器上安装 Nvidia 驱动程序和 CUDA 库。我们可以使用以下命令验证:
nvidia-smi
输出将显示活动 GPU 的数量以及基本利用率。
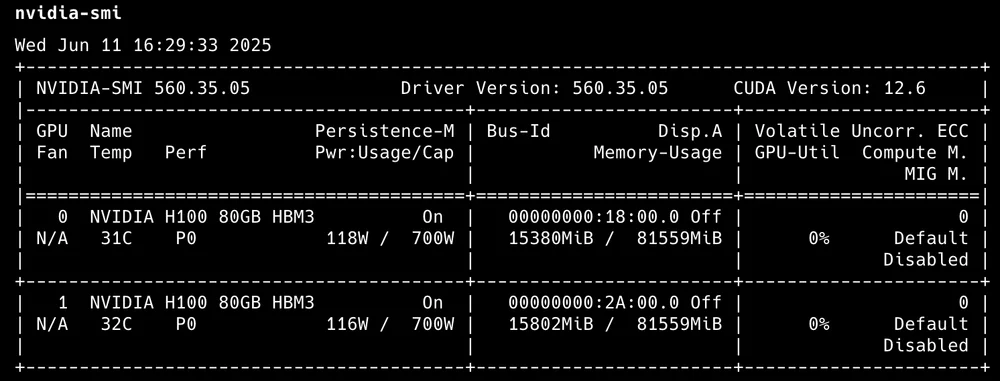
nvidia-smi 输出
- 安装 CUDA Toolkit
apt install cuda-toolkit
CUDA Toolkit 安装
就是这样!我们现在有一台带有 GPU 的 Linux Ubuntu 机器可以使用了。
NVIDIA Container Toolkit
简单来说,它是允许容器使用 GPU 的工具和库。我们将从安装 NVIDIA Container Toolkit 开始。此示例侧重于我相信许多人最常使用的 Docker 容器。
从这个示例中,我们将使用 Ubuntu 作为安装示例。
先决条件:
- 容器引擎(Docker、Containerd)
- Nvidia GPU 驱动程序
- 配置生产存储库
curl -fsSL https://nvidia.github.io/libnvidia-container/gpgkey | sudo gpg --dearmor -o /usr/share/keyrings/nvidia-container-toolkit-keyring.gpg \
&& curl -s -L https://nvidia.github.io/libnvidia-container/stable/deb/nvidia-container-toolkit.list | \
sed 's#deb https://#deb [signed-by=/usr/share/keyrings/nvidia-container-toolkit-keyring.gpg] https://#g' | \
sudo tee /etc/apt/sources.list.d/nvidia-container-toolkit.list
- 从存储库更新包列表
sudo apt-get update
- 安装 NVIDIA Container Toolkit 包
sudo apt-get install -y nvidia-container-toolkit
通过这 3 个步骤,我们将安装 nvidia container toolkit。下一步是配置我们的容器引擎以使用此工具包。
Docker 配置
sudo nvidia-ctk runtime configure --runtime=docker
sudo systemctl restart docker
对于其他容器引擎,您可以查看文档以获取更多详细信息。
对于 Kubernetes,我将把它作为另一个主要主题,因为还有另一个特定工具比在每个节点上安装 GPU 驱动程序和配置工具包更适合 K8S。
监控工具
安装和使用后,我们应该做的下一件事是监控使用情况。最简单的初始监控可能只是使用 nvidia-smi 来查看有多少 GPU 以及多少使用情况,但这还不够详细。所以我想推荐其他工具作为使用选项。
Nvitop
交互式 CLI,可以查看详细的 GPU 使用情况。安装非常简单:
pip3 install --upgrade nvitop
然后只需使用命令:
nvitop
您将通过终端获得一个交互式 UI

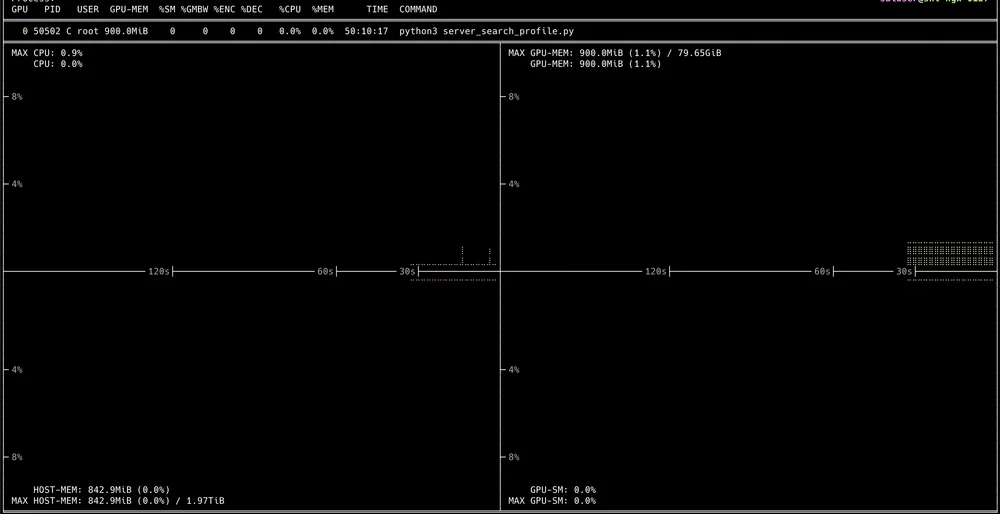
在那里我们可以向下钻取以查看每个正在运行的进程。
NVIDIA DCGM
来自 Nvidia 的官方工具,使用 Golang 开发,充当提取各种 GPU 集群指标的 API。
对于在常规 VM 上的安装,您需要先安装 GPU 驱动程序、Docker 引擎以及 Nvidia Container toolkit 才能使用 DCGM。
对于使用方法,我将保存它们以作为单独的完整文章编写,因为要充分使用 DCGM 需要与其他几个工具(如 Prometheus 和 Grafana Dashboard)一起使用。
最终总结
到目前为止,我认为阅读到最后的每个人都应该能够为团队使用提供带有 GPU 的 VM。如果我们逐渐理解它,我认为它比安装某些服务更容易。至于待处理的内容,请继续关注。它应该可以帮助您从开发到生产构建基础设施。