Data Extraction from Images Using Gemma3

For data extraction from images such as receipts, ID cards, or paper forms, traditional methods often use OCR (Optical Character Recognition) combined with rules or regex to extract data. This is complicated and difficult when data formats change.
In reality, we have another option: LLM Multimodal which can "understand images" and "answer questions" directly.
Concept
Multimodal LLMs can process both text and images simultaneously, allowing us to input images along with prompts such as:
This image is a restaurant receipt. Please extract data into JSON: restaurant name, date, food items, total amount
Code Example
Model
For this round, we'll try using gemma3-12b-vision
You can follow the Getting Started in the README for anyone who wants to try deploying the model themselves
Code
client-gemma3.ts
- Set a clear prompt about what this image is, what fields are needed with examples, what to do if not found, and specify that it must return in JSON format only. Here we'll also tell it to look at the
categoryto determine what it is. If it'sinvoice, then extract the fields we want, but if not, tell us what it is.
This is an image of a document. Please analyze the document and return a JSON object that strictly follows the schema below:
{
"category": string, // Document category: "invoice", "receipt", or "other-[description]"
"result": object | null // Invoice data if category is "invoice", otherwise null
}
If the document category is "invoice", return the result as:
{
"category": "invoice",
"result": {
"invoice_number": string, // e.g. "INV-2024-00123"
"invoice_date": string, // Date as shown in document (any format: DD/MM/YYYY, MM-DD-YYYY, YYYY-MM-DD, etc.)
"due_date": string | null, // Date as shown in document (any format) or null if not found
"total_amount": number | null, // Final total amount (e.g. 1234.50) in INR
"items": [
{
"description": string, // Name of the product or service
"quantity": number | null,
"unit_price": number | null,
"line_total": number | null
}
]
}
}
If the document category is NOT "invoice", return the result as:
{
"category": "receipt" | "other-[description]",
"result": null
}
DOCUMENT CATEGORY GUIDELINES:
- "invoice": Only tax invoices, billing invoices, commercial invoices
- "receipt": Payment receipts, transaction receipts
- "other-[description]": For any other content, describe what you see after "other-"
Examples: "other-id_card", "other-child_photo", "other-certificate", "other-bill", "other-menu", "other-text_document"
IMPORTANT INSTRUCTIONS:
- Only extract invoice data if the document category is clearly "invoice"
- For receipts, use exactly "receipt" as the category
- For anything else, use "other-" followed by a brief English description of what you see
- For dates, extract them exactly as they appear in the document - do not convert or reformat
- For all non-invoice documents, set result to null
- Do not guess or fabricate values
- Return ONLY the JSON object directly. Do not wrap it in markdown code blocks (\`\`\`json\`\`\`)
- Do not include any explanation, comments, or extra text before or after the JSON
- Your response should start with { and end with }
- The response must be valid JSON that can be parsed directly
- Pass image through
image_urltype in content message back and forth
const { data } = await axios.post(
`${process.env.BASE_URL}/chat/completions`,
{
model: "gemma3-12b-vision",
messages: [
{
role: "user",
content: [
{
type: "text",
text: prompt,
},
{
type: "image_url",
image_url: { url: `data:image/jpeg;base64,${image}` },
},
],
},
],
},
{
headers: {
Authorization: `Bearer ${process.env.API_KEY}`,
"Content-Type": "application/json",
},
}
);
client-openai.ts
For cases using other Models that support OpenAI Completions and Multimodal
Result
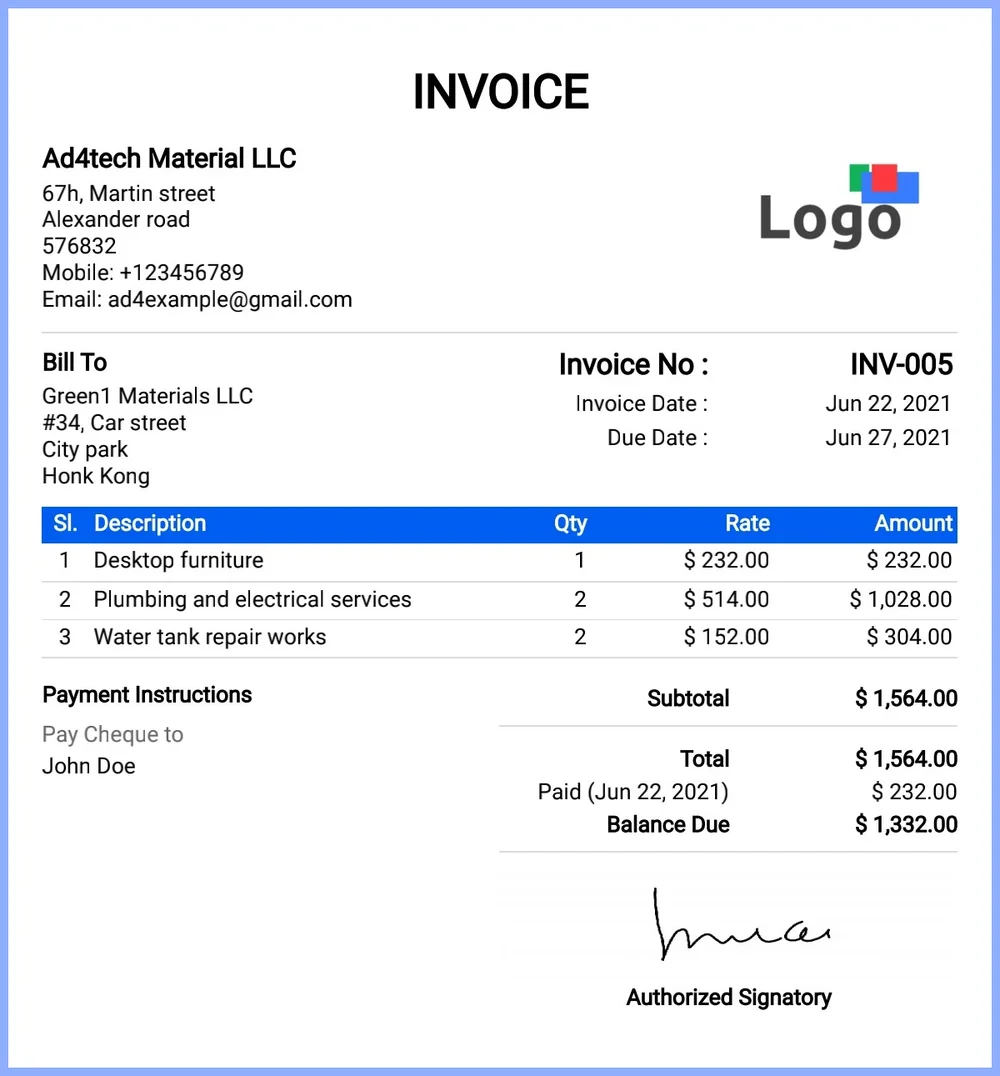
{
"category": "invoice",
"result": {
"invoice_number": "INV-005",
"invoice_date": "Jun 22, 2021",
"due_date": "Jun 27, 2021",
"total_amount": 1564,
"items": [
{
"description": "Desktop furniture",
"quantity": 1,
"unit_price": 232,
"line_total": 232
},
{
"description": "Plumbing and electrical services",
"quantity": 2,
"unit_price": 514,
"line_total": 1028
},
{
"description": "Water tank repair works",
"quantity": 2,
"unit_price": 152,
"line_total": 304
}
]
}
}

{
"category": "invoice",
"result": {
"invoice_number": "100",
"invoice_date": "1/30/23",
"due_date": "1/30/23",
"total_amount": 420,
"items": [
{
"description": "20\" x 30\" hanging frames",
"quantity": 10,
"unit_price": 15,
"line_total": 150
},
{
"description": "5\" x 7\" standing frames",
"quantity": 50,
"unit_price": 5,
"line_total": 250
}
]
}
{
"category": "receipt",
"result": null
}
Advantages
- Works with multiple formats (even if layout changes)
- Can specify desired data through prompts
- No need to write regex or document-specific templates
- Can add conditions like if it's a then extract b
- Can perform classification/validation
Cautions
- Relatively high cost (charged by token)
- Accuracy depends on prompt and image clarity
- Should have fallback or validation in case model gives wrong answer
Compared to OCR Approach
- OCR: Convert image to text
- OCR Post-processing: Improve text obtained from OCR to be more accurate
- Text Extraction & Cleaning: Extract important text and clean data
- Document Structure Understanding: Understand document structure (receipts, invoices, approval reports)
- Named Entity Recognition (NER): Identify company name, date, amount, document number
Conclusion
Using Multimodal LLM for data extraction from images is an excellent approach, especially when documents have many fields and we only want to extract specific fields, layouts may not be consistent, or there are certain conditions for data extraction. We can control it through prompts without building complex parsing systems. This means we no longer need to stick to the idea that this type of work must only use OCR and then sit and write regex or analyze further to extract the data we really want.
The examples given are simple data extraction, but in reality, there are many other approaches we can take. We can add certain conditions, use it for Classification/Validation.
Float16
Managed GPU resource platform for developers. Experience the cheapest serverless GPU in spot mode and the fastest GPU endpoint in deploy mode.
Connect with us:
- Medium : Float16.cloud
- Facebook : Float16.cloud
- X : Float16.cloud
- Discord : Float16.cloud
- Youtube : Float16.cloud